数据类型大概是大家上手EZDML后面临的一个较大的困惑,因为EZDML并没有直接提供大家熟悉的数据库类型,而是只提供了一些逻辑数据类型:
- String——文本
- Integer——整数
- Float——浮点数
- Date——时间
- Bool——真假
- Enum——枚举
- Blob——文件
- Object——对象
- Calculate——计算
- List——列表
- Function——方法(函数)
- Event——事件
可能前面几个还勉强能理解,后面那几个是什么鬼?
基本数据类型
引用一段以前写的文档说明供参考:
为什么字段的数据类型那么少?
本工具以简单设计为主,所以把常用的数据类型归纳为以下几种了:文本、整数、浮点数、时间、真假、枚举、文件(二进制)。比如字符串VARCHAR、VARCHAR2、NVARCHAR、CLOB(长度超过数据库限制时会自动转用CLOB),在我看来都是一个类型,只是换了个马甲而已。这样做的好处,主要是跟编写代码比较接近,另一个是跨数据库时比较方便。
大部分情况下我们会经常使用一种基本物理类型,比如常用varchar对应String,这个varchar就可以默认预先设置好。偶尔需要区分多个类型时,你可以在选定基本逻辑类型后,在字段的类型名称上做补充,比如基本类型选String,类型名称写NCHAR。
如果你的场景经常要区分数据库的各种物理数据类型,那EZDML可能不是最好的选择。
编程数据类型
这节是一些充数的瞎聊内容,可以跳过。
继续聊数据类型前先说明一点,作者主职是一个独立程序员(注意这是个贬义词),没有专业的DBA和项目产品经理参与,因此我写EZDML这个工具更多是从自身的角度出发的(就是独断专行了)。
然后来看个古老版本的截图,可以看出最开始是没有后面几个类型的,只有前面的基本数据类型:
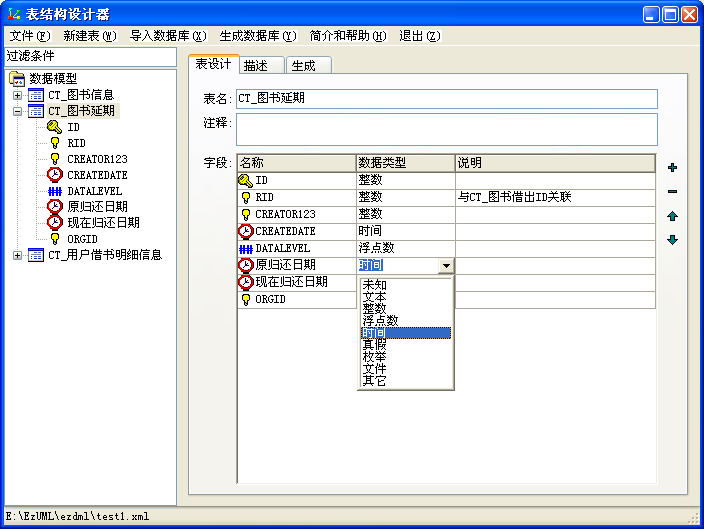
而且最开始是没有物理类型也没有长度设置的,我的初衷是希望更多关注表结构本身而不要纠结于物理类型,也不要纠结于字段长度控制,你只要告诉一下这个字段是字符串还是数字日期就行了。
其实说这么多都是借口,最重要的原因还是在于我自己,因为我是程序员,我写程序时经常碰到的数据类型就是这几种,所以很自然就抽象出来这几种数据类型了。
我当时只会用ORACLE(和FoxBase之类的),那时ORACLE数据库里是没有bool真假和枚举类型的,也没有专门的整形,我仍然强制加了上去,因为我写程序时有这些类型。
抽象类型在跨数据库时是挺有好处的,但其实是后来才发现的,因为我一开始只会用ORACLE,当时并没有想到这一点。
另外从图中也可以看出,最开始也没有区分物理名称和逻辑名称,因为我都是直接用中文表名和中文字段名。直到现在,我自己设计表结构的话仍然是尽量这么干的,只设置逻辑类型,不设置物理类型,不设置长度精度,直接用中文表名和中文字段名,简单、明了,Easy。
当时很流行UML(统一模型语言),于是我就取名Easy DML(数据模型语言),这就是EzDML的由来。会有人说你干嘛不直接用UML工具呢,嗯,因为我想设计表结构啊;为什么表结构里有一堆程序的类型呢,因为我还想在表结构的基础上搞点其它东西。
当然,后来还是不能免俗,把字段长度和精度加上了,把物理名和逻辑名分开了,因为理想和现实有差距,很多项目不由你说了算,理想很Easy,现实很残酷。
程序数据类型和属性
这一节也是一些凑字数的瞎聊内容,可以跳过。
以程序员的角度来看就很好解释了。EZDML搞了一段时间后,我发现用它来生成代码挺方便的,于是出于个人喜好,我加上了对象、列表、事件、方法类型,作为一个程序员,有些想法是很合理的对吧。
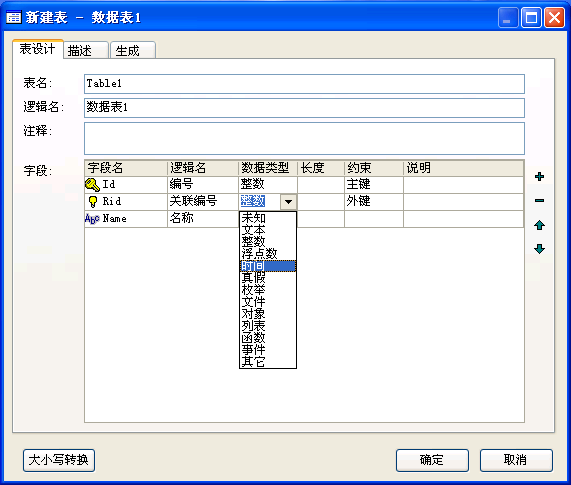
后来又增加了计算类型。这些扩展的程序数据类型,生成数据库表结构时并没什么用,会自动过滤掉,不影响生成结果。
然而这么多年下来,我发现自己也不常用这几种类型,有需要时直接写代码更快,有点多余了。
我还给字段加上了一堆乱七八遭的属性,编辑器类型、下拉列表、显示格式之类的,就是现在的编辑器界面和业务逻辑的设置部分:
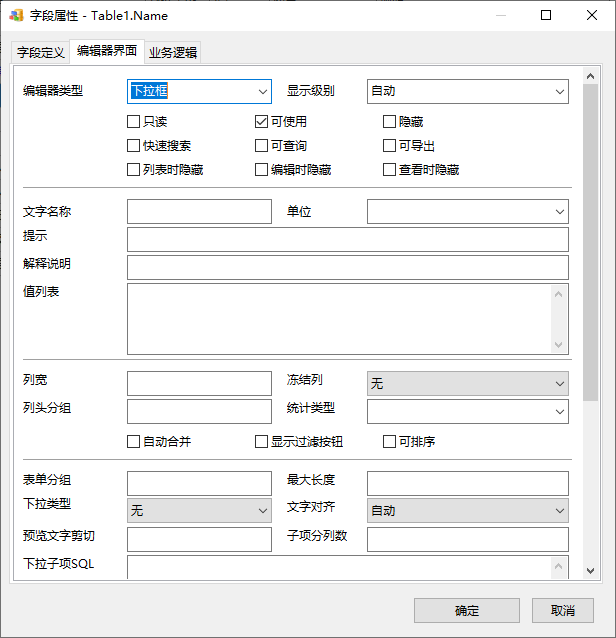
前面说了,作为一个程序员,有些奇怪的想法是很合理的;中国的软业开发你懂的,程序员经常需要身兼多职。这工具一开始就主要是为我自己服务的,因此虽然取名为表结构设计,但并没有按ER设计的套路出牌,中间干了不少私活,正事可能却没干多少,正如我之前文档中提过的:
EZDML表面上是数据库表设计工具,可实际上为数据库服务的并不深入,更多是为了搞代码、脚本、文档之类的不务正业的东东。如果你想用它来维护触发器、存储过程、表空间、同义词、分区之类的,那你很可能要失望了,可能你想要的功能没有,你不想要的、没什么暖用的东西却很多。
不过当时这部分我觉得对别人完全没用,发出来会被人嘲笑,所以对外发布的版本我就把这些部分隐藏了。后来有一天有网友提出能不能加些类似的东西,我才发现哦原来不是只有我一个人有这种想法,程序员都喜欢自己生成各种东西,于是就光明正大的放出来了。
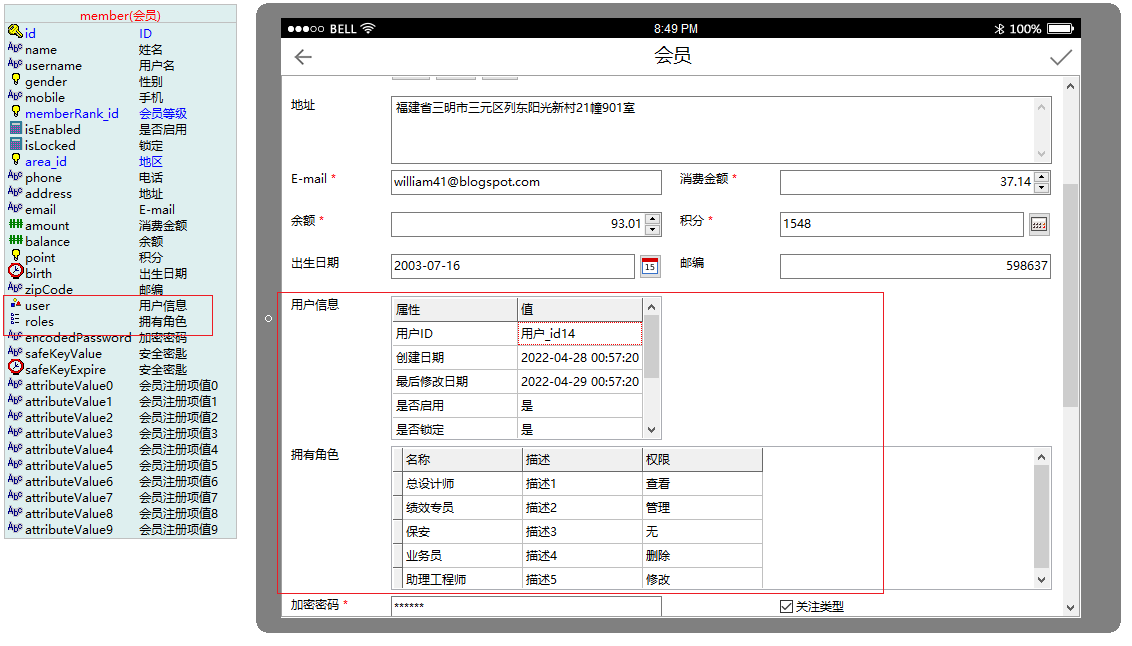
之前说扩展类型似乎没什么用,但后来生成界面代码时我终于又发现有用了,比如表单或接口中要显示或返回引用的外建表和子表,就需要用到Object和List了:
如何指定物理类型
既然默认只有逻辑类型,那如果我非要指定物理类型,比如name String(255),我非要指定为NVARCHAR,要怎么操作呢?
答案是在字段属性中的“类型名称”中指定就可以了:
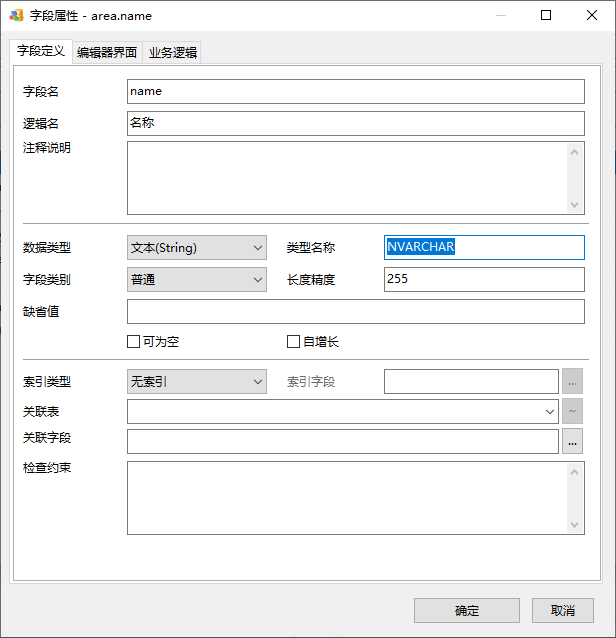
但是,请大家用这个“类型名称”前,一定要往下看到“指定默认物理类型”一节。
这个“类型名称”隐藏得较深,没有任何提示、下拉框等辅助功能,只能一点一点手敲,原因就是作者不太希望大家去设置这个物理类型,而是想找一些变通的办法(请继续往下看)。一开始是麻烦点,但长远来看是有好处的。
关于CLOB类型
EZDML没有专门定义CLOB类型,而是把CLOB归纳到String类型了,只要把字段设置成字符串类型,并把长度设置成超过VARCHAR能承受的最大长度(建议为99999),生成SQL时就会自动转用CLOB类型。
指定字符串长度时,想要CLOB时建议设置为99999(连按5下就好)。最好不要取6000、8000这种尴尬的长度,因为它在ORACLE数据库中超过4000长的VARCHAR2是会转成CLOB,但在其它一些数据库(如POSTGRESQL)是支持8000长的VARCHAR的
关于整数和BigInt类型
整数Integer在ORACLE中是不存在专门类型的,确实ORACLE也有一个integer类型,但它其实是Number数值类型子集(相当于别名,据说对应是Number(38),我没有研究过),存储运算方式也是按Number来处理的,因此一般不认为是其基本内置的数据类型(好像一般也没有人直接用Integer类型)。EZDML默认把整数映射为ORACLE的NUMBER(10)了,并允许随意指定长度精度。
但在MYSQL和POSTGRESQL中,整数类型不仅独立于浮点数存在,还细分成了好几种:tinyint、smallint、midiumint、int、bigint。各自的存储、索引和处理方式也有差异。
当然你可以直接在整数字段的类型名称中为每个字段指定上述类型,但EZDML也支持按指定字段长度自动匹配为相应的类型:
- 小于等于4:tinyint
- 5、6:smallint
- 7、8:midiumint(MYSQL),integer(PQ)、int(其它)
- 9、10、11:integer(PQ)、int(其它)
- 12及以上:bigint
比如Integer(5)在ORACLE中生成为Number(5),在MYSQL中就会生成为smallint。
默认的整数可能对主外键来说偏小,数据量大时容易溢出,可以设置中指定整数形主外键采用BigInt类型(ORACLE中为Number(20) )。
模型图物理类型显示
模型图中按F7是可以切换视图的,以自带demo为例,切换到物理视图是这样的:
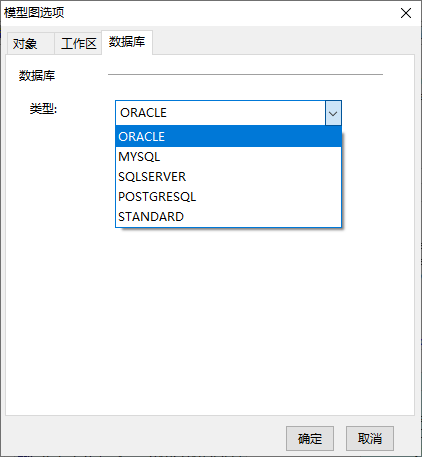
这个物理视图多半不是你的数据库类型,需要在模型图样式里设置。比如我常用的是ORACLE:
设置完后,模型图就会换成ORACLE的物理类型了:
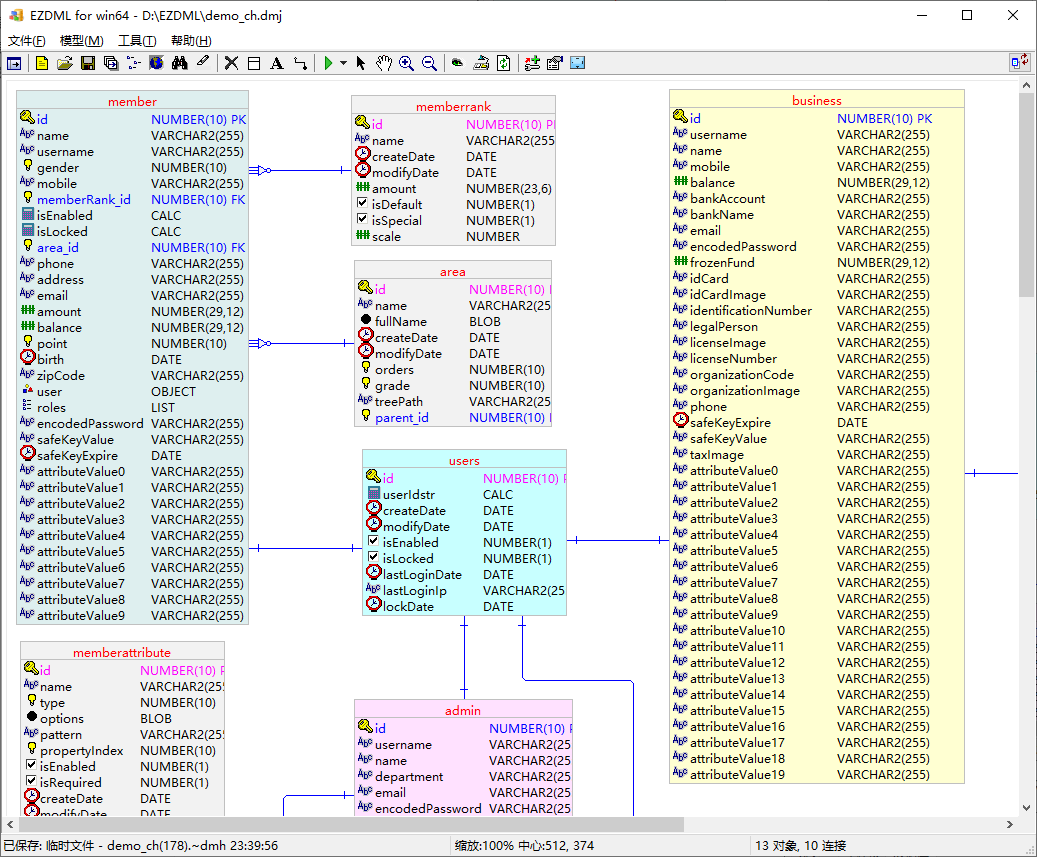
另外,要注意一点是,导出EXCEL时,字段类型是跟模型图视图有关的,模型图上显示逻辑类型时导出EXCEL字段是逻辑类型(如String);模型图显示物理类型时,导出EXCEL的是物理类型(如varchar)。
指定默认物理类型
对于文本、整数、浮点数、时间、真假、枚举、文件这些基本类型,EZDML默认会给它们在数据库的物理类型作一个对应。比如最常见的字符串,在各数据库中的默认物理类型为:
- ORACLE:VARCHAR2(4000)
- MYSQL:VARCHAR(4000)
- SQLSERVER:VARCHAR(4000)
- SQLITE:TEXT
- POSTGRESQL:varchar
其中字段长度4000是默认长度,在字段没有指定长度时会采用默认长度;如果字段有指定长度则以字段指定值为准。
在“工具|设置”的“字段类型”里列出了所有数据库的默认物理类型。里如果你觉得默认的类型不是你想要的,也可以直接在这里修改(如果直接改“默认”列,则对所有数据库生效)。
比如喜欢用NVARCHAR(2000)的:
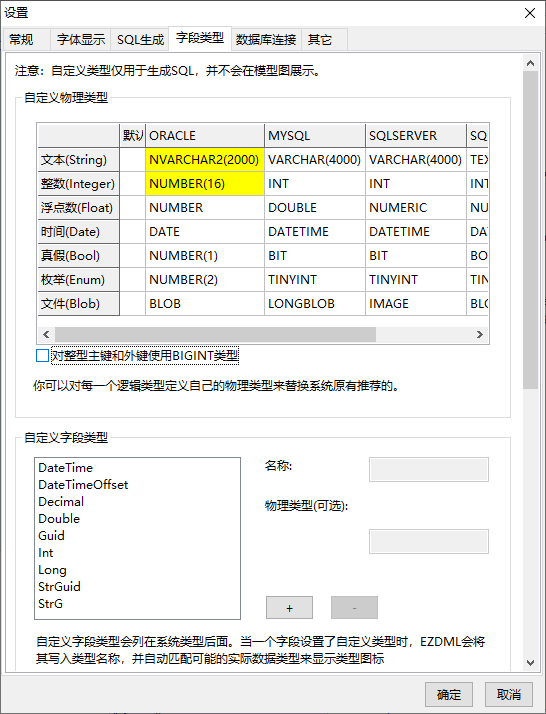
(注:如果要取消已设置的物理类型,直接将其清空即可)
设置后生成的SQL就会相应变化:
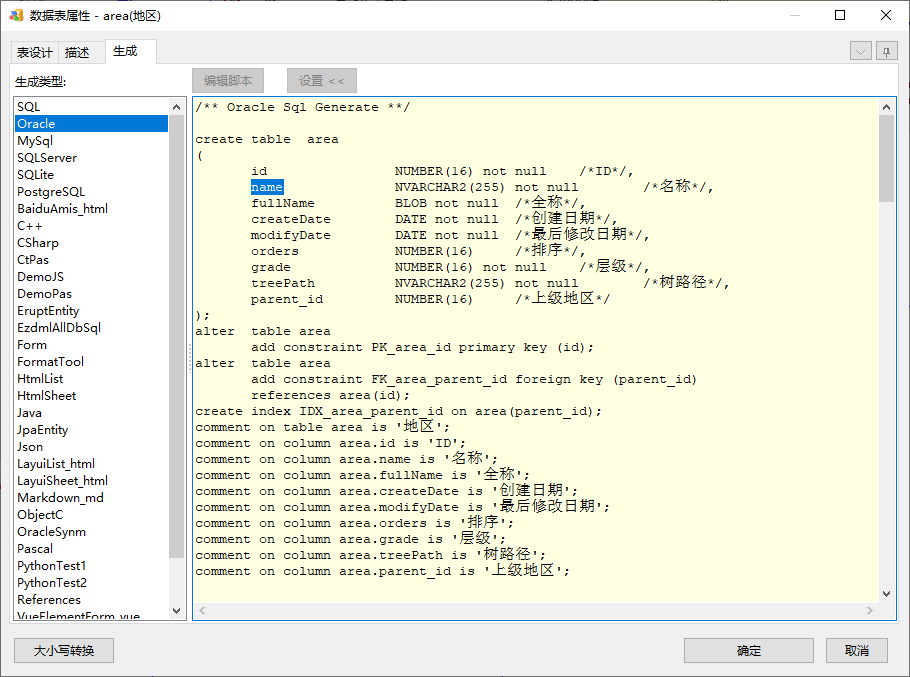
指定单个字段的物理类型
比如还是ORACLE的字符串String类型,如果系统中绝大部分字段的默认物理类型VARCHAR2都没问题,但就是area.name我希望改成NCHAR,这时你可以直接在字段的类型名称中填入CHAR:
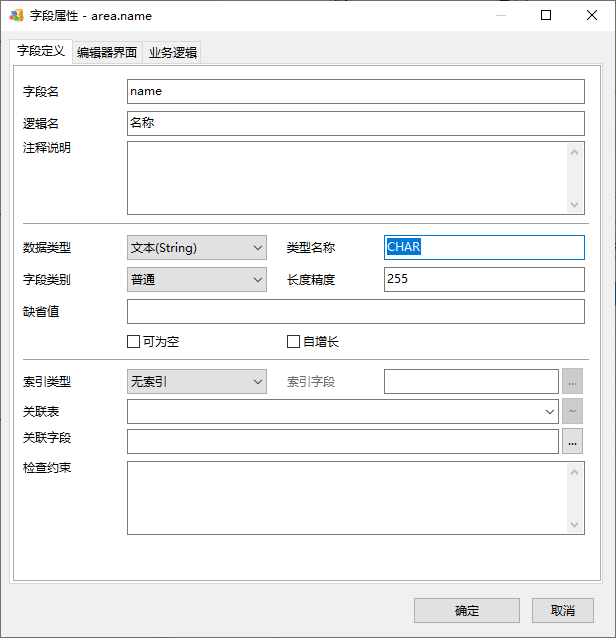
指定类型名称后,这个字段生成数据库SQL时将直接用这个类型,不再使用默认的物理类型了;与此同时,其它未指定类型名称的字段仍然使用默认物理类型:
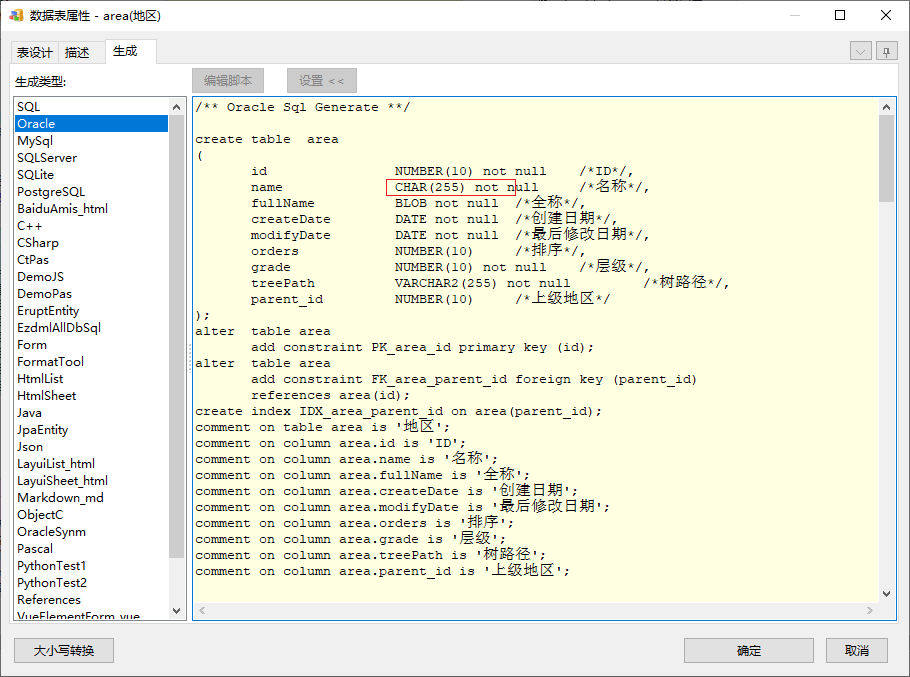
自定义字段类型
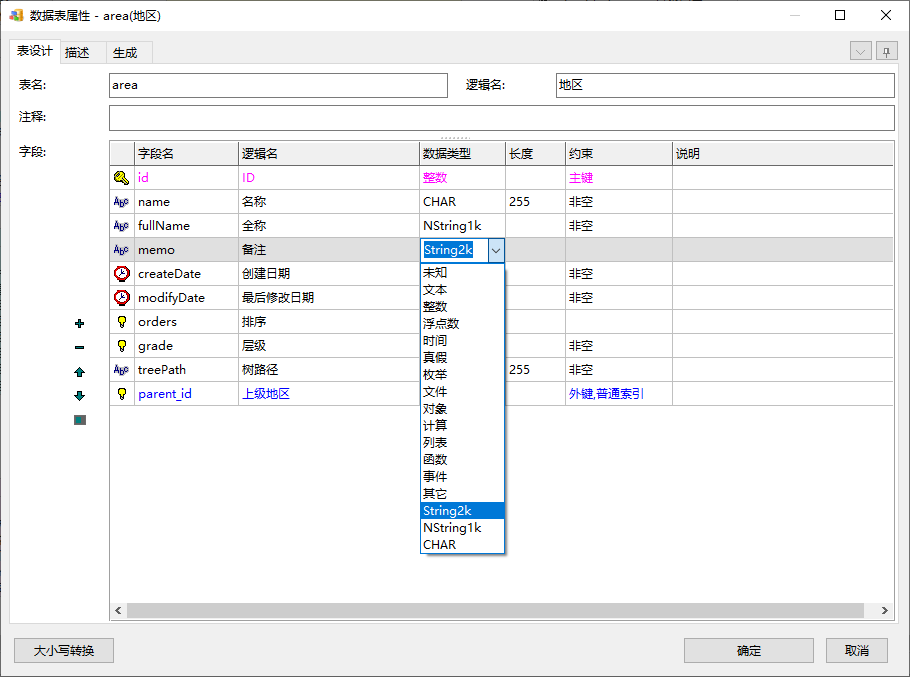
虽然可以指定全局所有字段的默认类型,也可以指定单个字段的类型名称,但可能还有一种情况。比如这一批字段都会用VARCHAR2(2000)类型,另一批字段都是用NVARCHAR(1000)类型,还有一批是用CHAR类型长度不确定,这三种都经常要用,每次都敲键盘很累,这时就可以设置自定义字段类型。
进入“工具|设置”的字段类型设置界面,添加一个自定义字段类型,取名为String2k:
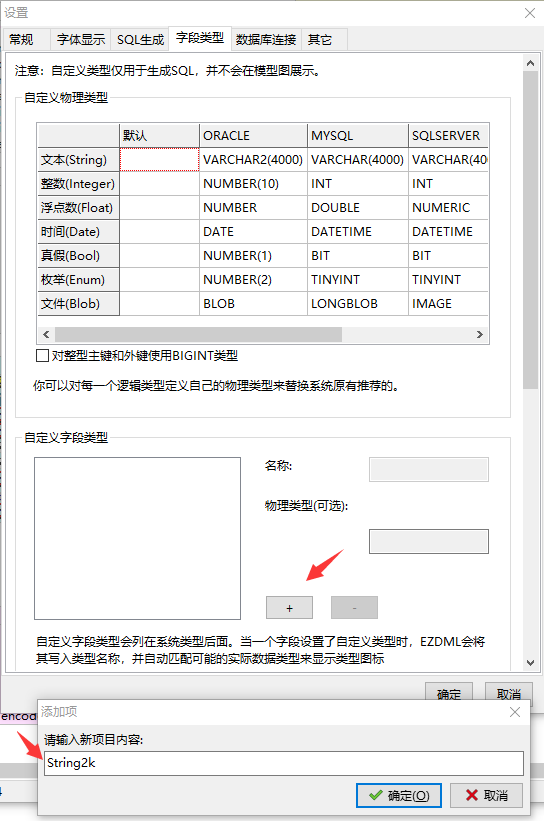
然后输入物理类型为VARCHAR2(2000):
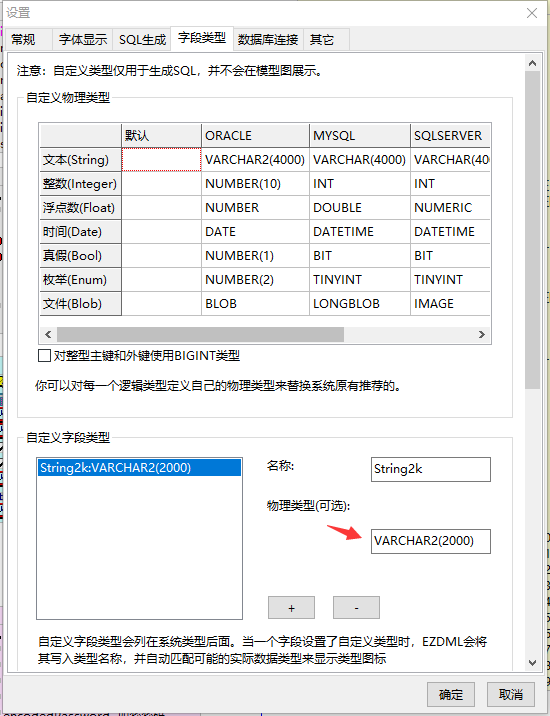
同样的再增加NString1k和CHAR类型:
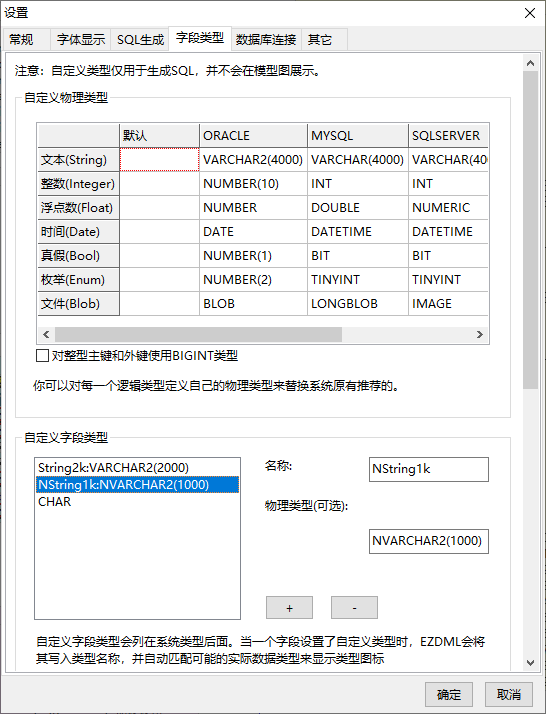
注意CHAR类型我没有指定对应的物理类型,不指定时物理类型取值与别名相同,而CHAR本身就是一个物理类型了。
设置好后,数据类型下拉列表就会增加这几项:
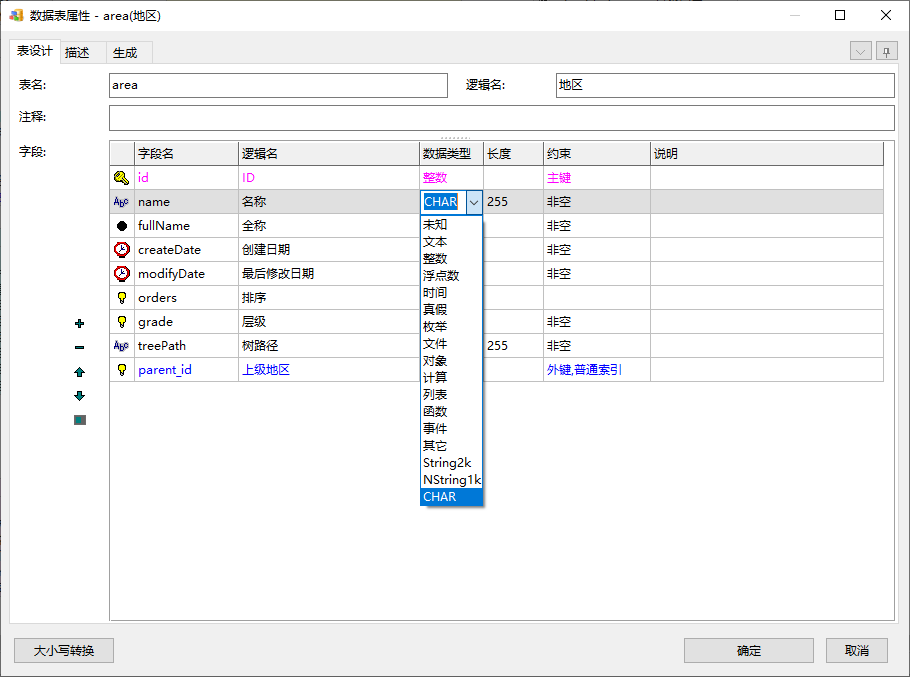
我们多设置两个字段:
最终生成SQL如下:
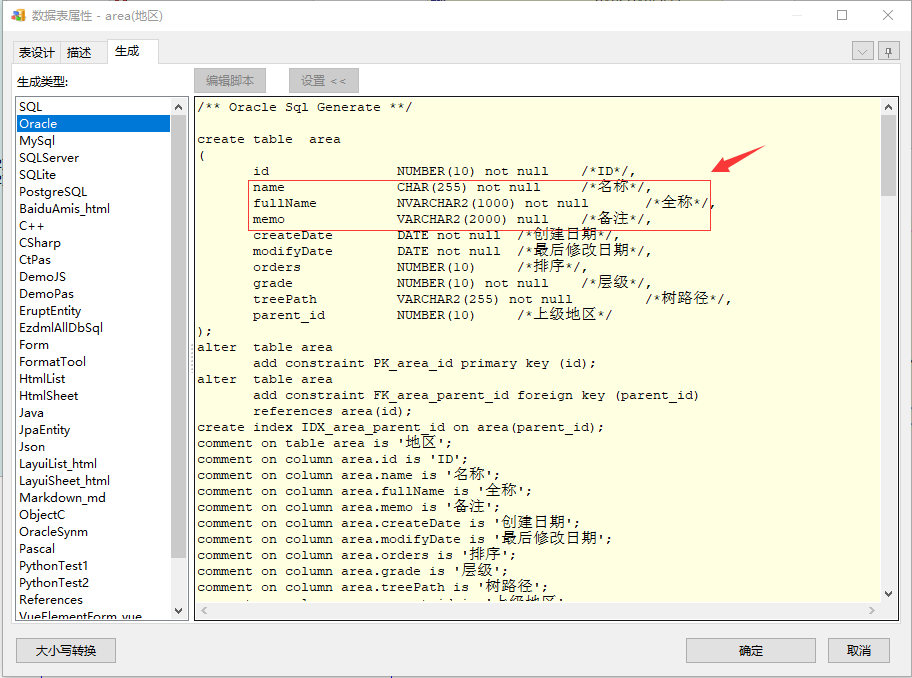
注意自定义字段类型其实是保存到类型名称里了,等于是指定了物理类型。但字段仍然需要有一个基本的逻辑类型。上述情况我们指定String2k和NString1k时,你会发现EZDML自动把它们的逻辑类型设置成字符串了,原因是它自动匹配包含string、char、text等字样的就会自动识别为字符串;如果自动识别失败,你可能仍然需要手工指定。
字段类型替换
除了上述的物理类型设置方法,我们还可以在生成SQL时对字段物理类型进行替换。比如下面的配置会把所有VARCHAR2(400)的字段变为NVARCHAR(200):
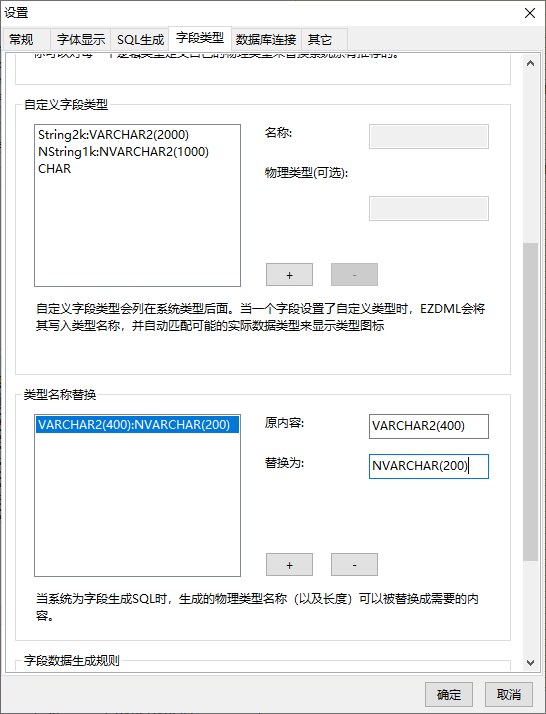
原理也简单,就是生成字段类型SQL后匹配查找替换一下。比如我们把area.name改成字段串400:
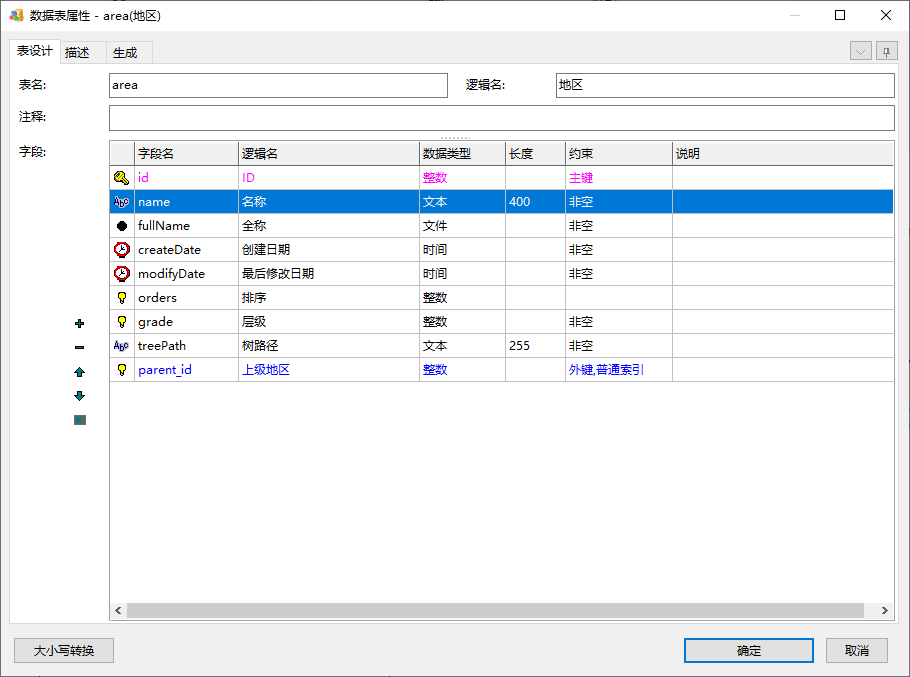
生成SQL就会变成NVARCHAR(200):
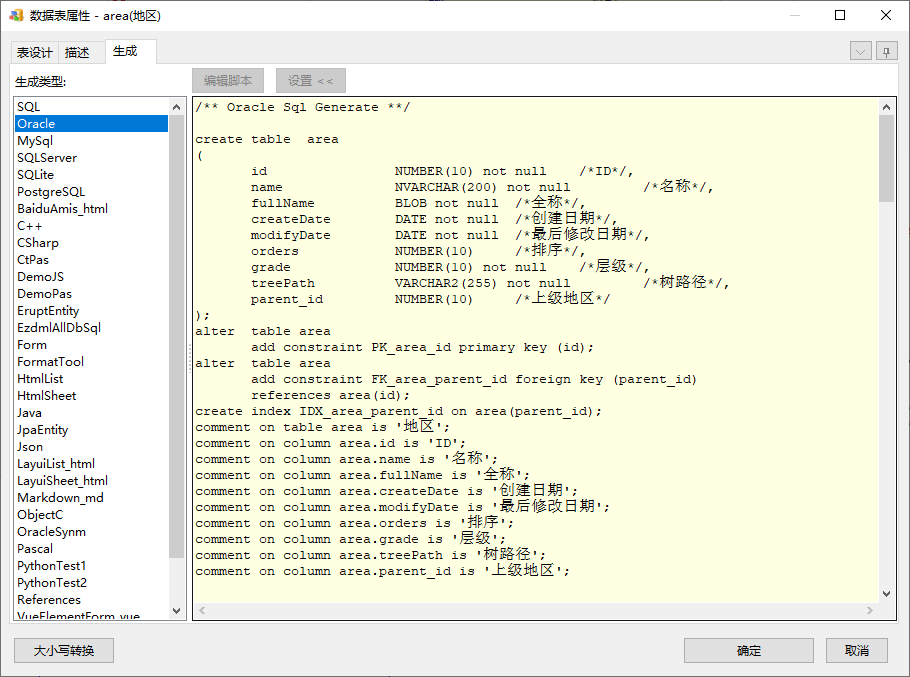
请注意只有400的name的类型变化了,treePath的VARCHAR2(255)是没有变的。
全局脚本替换
嗯,终于轮到脚本了,终极装X神器上场。这个脚本引擎我感觉可能更多时候是我自己的玩具,我一个人也能玩得不亦乐乎。经常有同事向我问一些问题时,我都能用脚本把人唬得一愣一愣的。但脚本还是相对复杂,大家了解一下就好。
比如你需要针对所有名称为name且长度为255的字符串字段,生成SQL的物理类型由VARCHAR2(255)改为NVARCHAR(100),这么个破需求。
当然可以用脚本遍历所有字段自动给字段的类型名称和长度赋值,但这不优雅,也不能对以后新建的表字段生效。
接下来我们优雅一点,你可以仍然只指定为name String(255),然后我们执行“工具|编辑全局事件脚本”,第一次执行时会提示:
点“是”创建后,出来脚本:
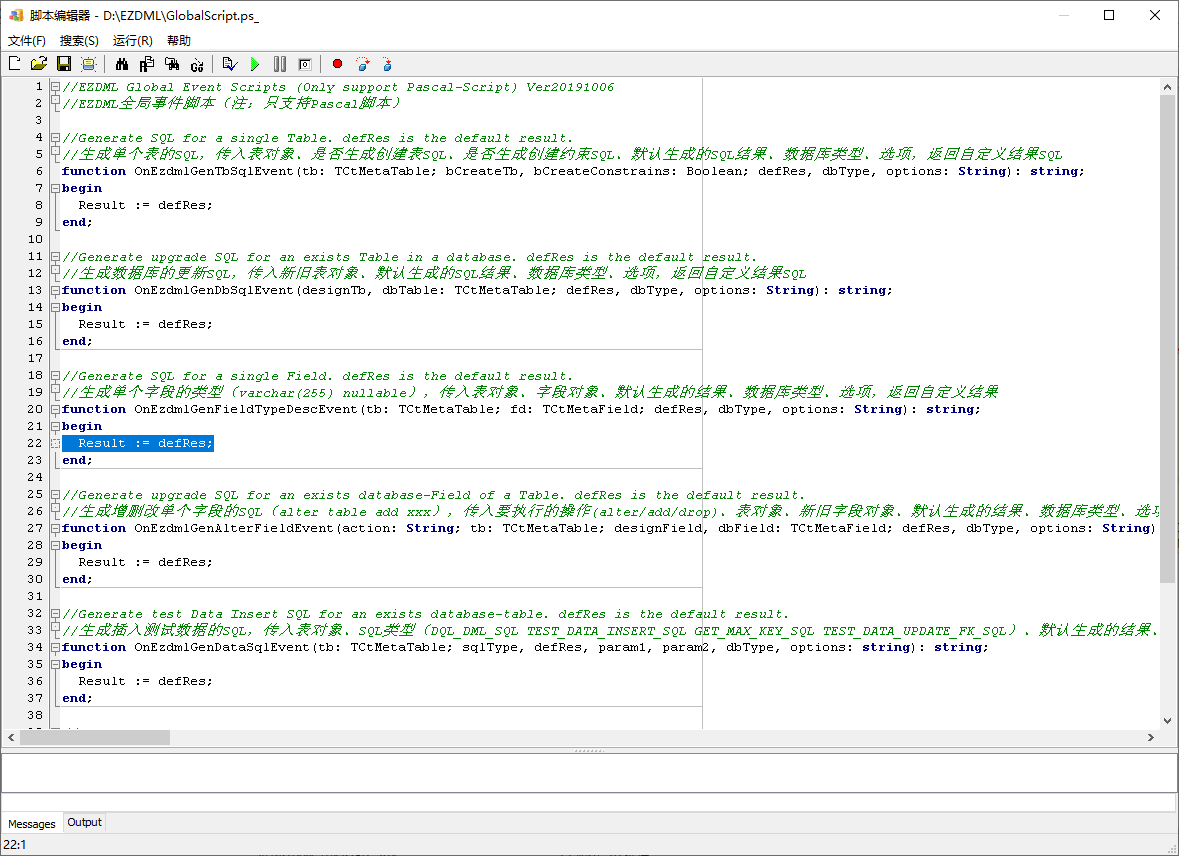
这个脚本是PASCAL的。嗯,由于JS效率较低,这个脚本调用频繁,很需要性能,因此我没有做JS版的支持。但你并不需要精通PASCAL,大部分情况下你只需要了解少数几个函数写法就够了。
第20行那个OnEzdmlGenFieldTypeDescEvent就是我们要关注的事件了。defRes是默认结果,示例格式为varchar(255) nullable,显然它还包含了别的内容,不过不要紧,我们查找替换就是了。编写脚本如下:
1 | //Generate SQL for a single Field. defRes is the default result. |
编译运行通过:
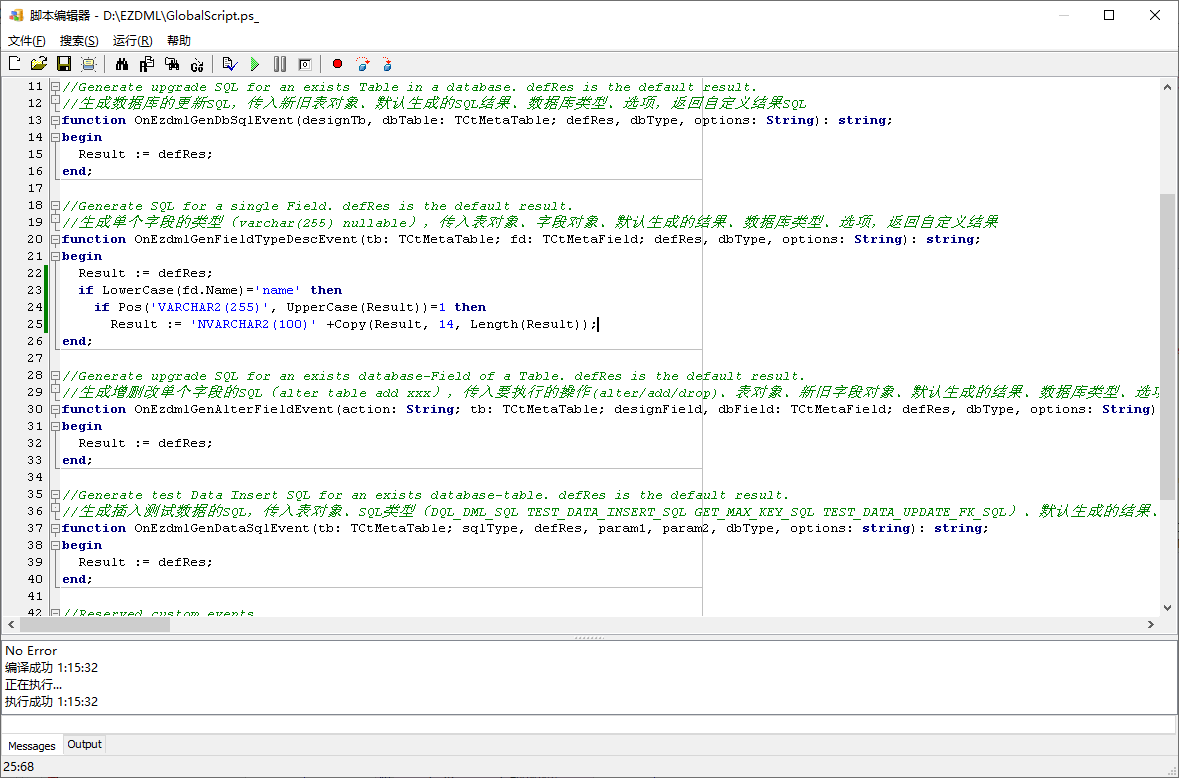
回到模型,这时就会发现,所有长255的name字段生成的Oracle SQL都变成了NVARCHAR2(100)了,而其它字段并没有变化:
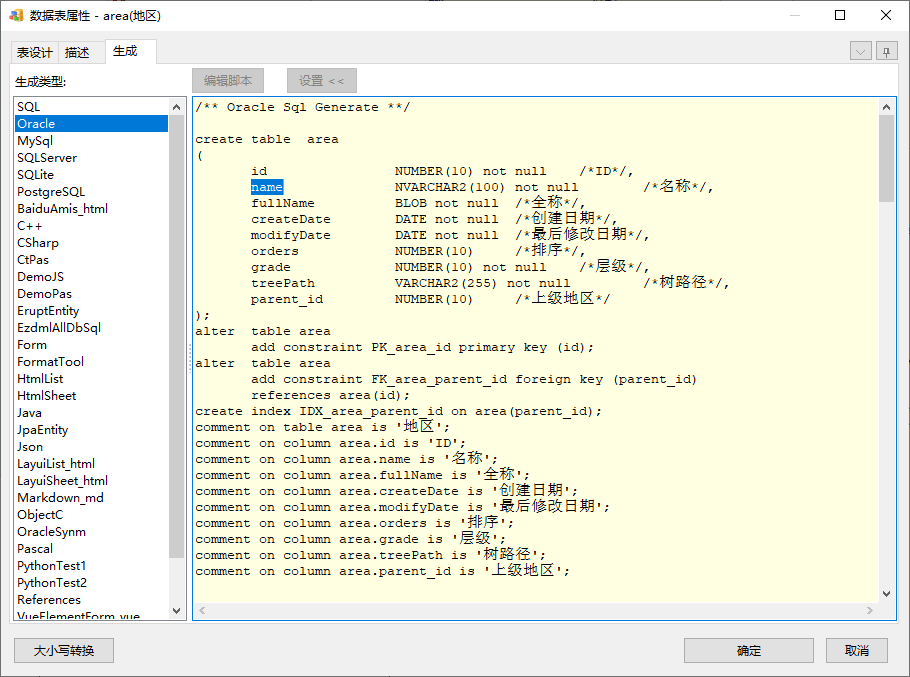
即使同是area.name字段,生成其它数据库的也没有变化,因为其它数据库默认不生成VARCHAR2类型:
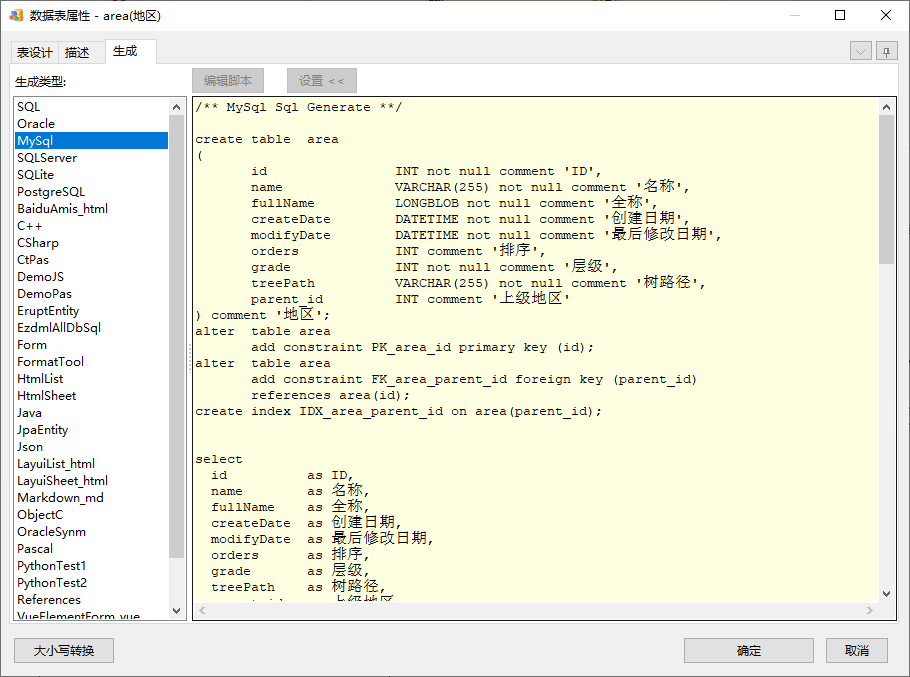
OK,今天到此结束。