理论上EZDML可以通过JDBC连接所有数据库,之前有网友跟我说EZDML通过JDBC连接hive有问题,我自己不玩数据仓库,对hive不熟,不过我想正常来说都是JDBC封装了,不应该啊。因此这几天我就亲自试验了一下,看看到底是什么情况。过程中发现要修改JDBC和EZDML代码,因此也记录一下相关的处理过程供参考。
先说结论:EZDML最新版3.42后可以连接hive,旧版有问题(本文是从旧版开始的,弄完这文章后新版才出来)。
安装hive
hive安装网上有很多文章了,这里简单介绍下我的安装过程,hive老手可以跳过这一节。
一开始是想自己从零开始安装的,不过这玩意确实有点复杂,各种版本引用问题,照着网上的文章折腾半天后,我觉得还是找个别人装好的镜像算了。
我找的是厦门大学数据库实验室林子雨老师的大数据Linux实验环境虚拟机镜像文件,里面已经安装好所需软件,内容非常全面:
1 | Ubuntu16.04 |
感谢林老师的奉献!下载地址:
1 | http://dblab.xmu.edu.cn/blog/1645-2/ |
下载后会得到一个6G的ova公开虚拟机格式文件:
用VirtualBox或VMWare都可以导入打开,我是用VMWare:
有个警告,可以点“重试”忽略:
然后等上十几分钟,估计是在解压缩:
导入成功:
开机,原来是个优麒麟系统:
默认有三个用户,我们用hadoop,密码也是hadoop:
登录后看下IP:
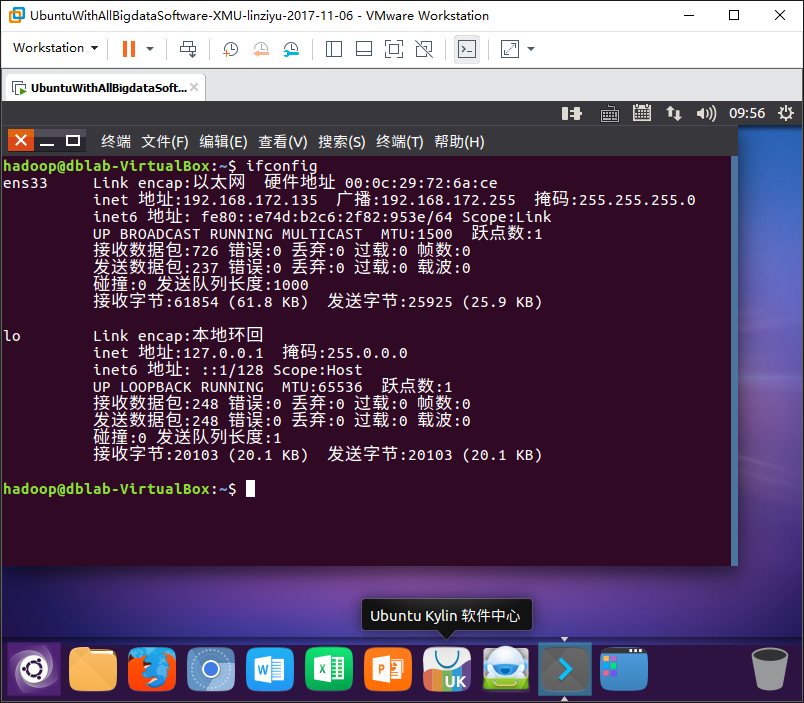
然后在本机用putty之类的终端工具连接,我这里用MobaXterm(连不上的,可能要检查下防火墙之类的):
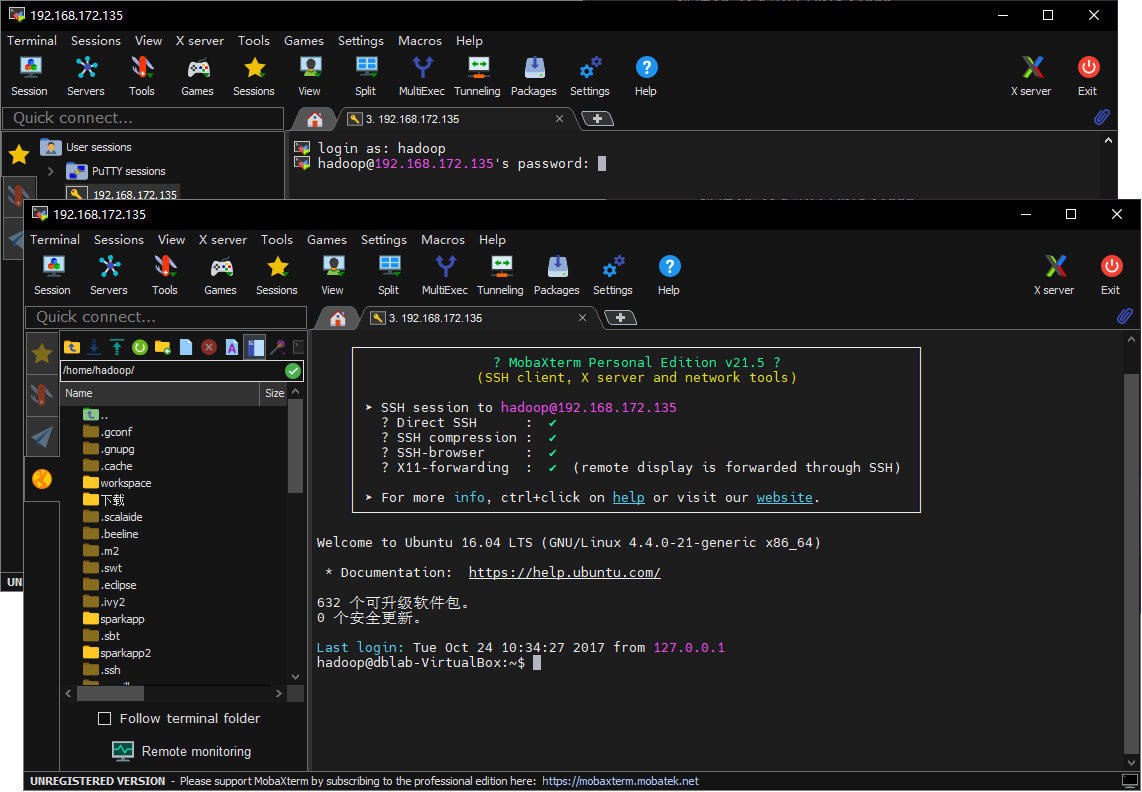
直接运行hive试试:
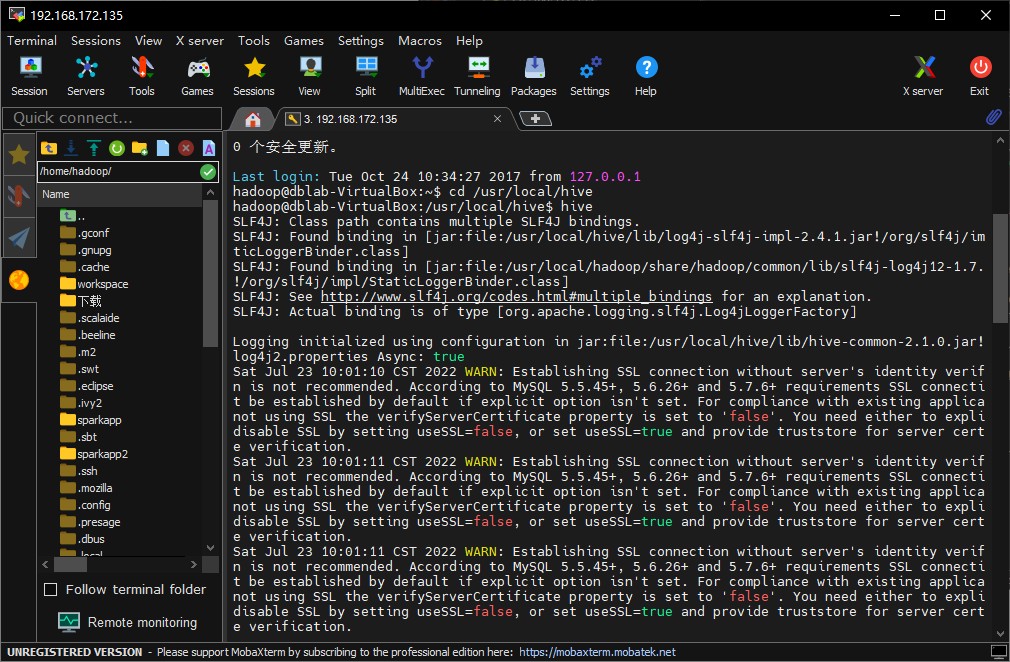
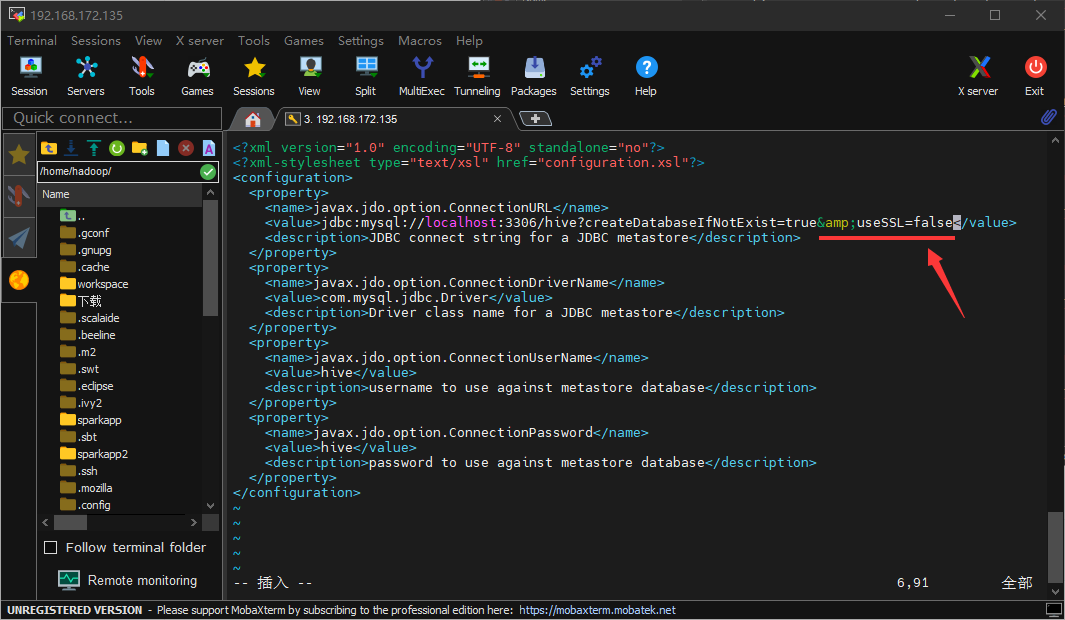
看起来是连接mysql的配置要改一下,运行以下命令:
1 | cd /usr/local/hive/conf |
按i进入编辑模式,修改JDBC连接的URL,按提示说明添加useSSL=false参数,然后Esc并输入:wq保存退出:
再次运行hive:
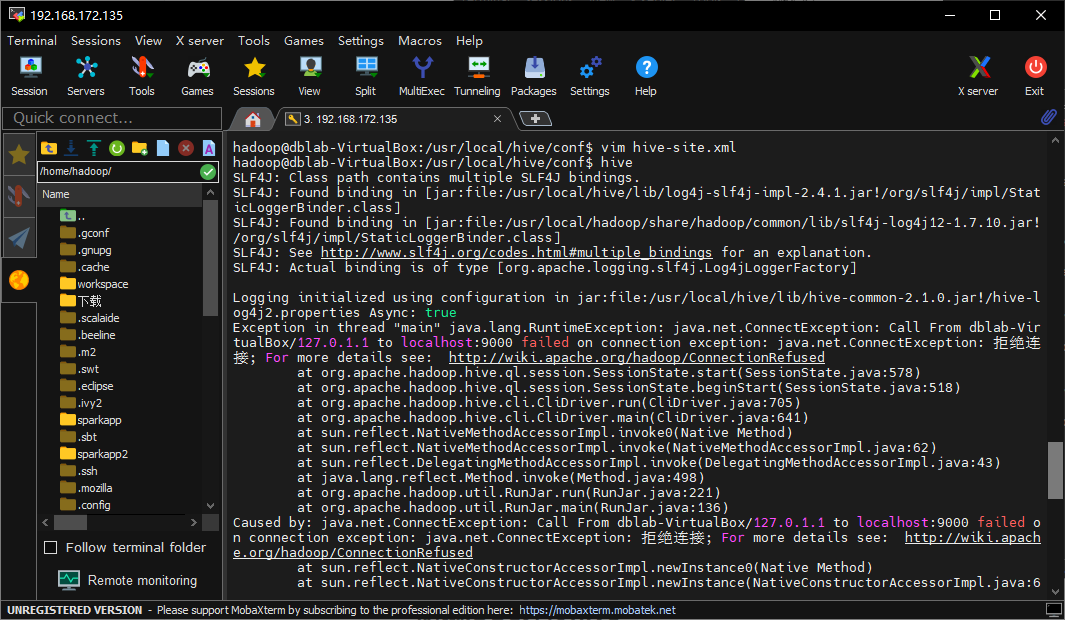
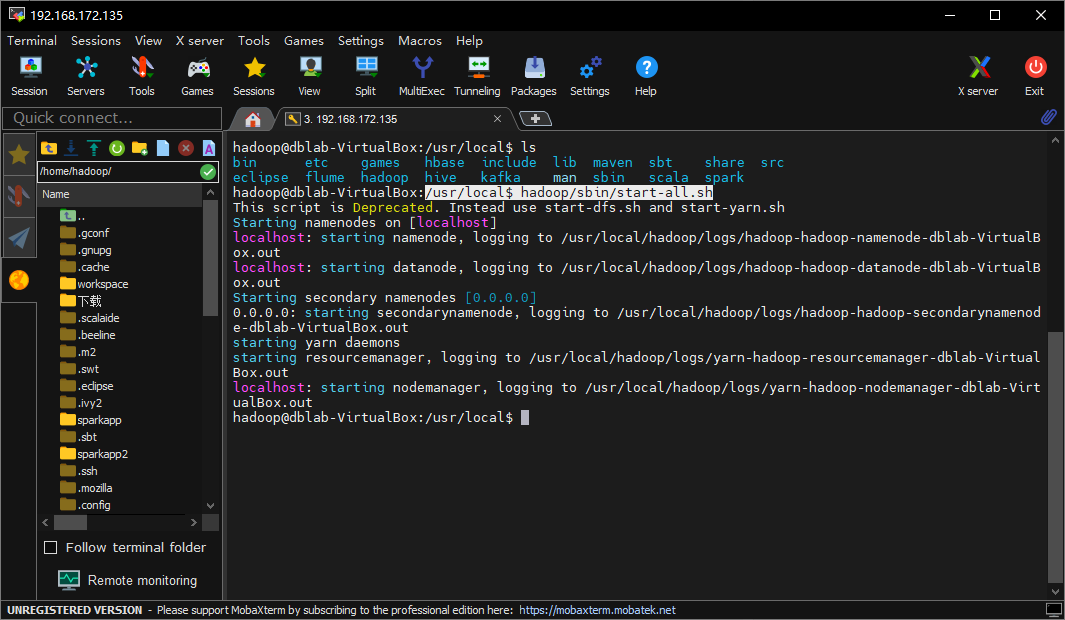
嗯,这会换了一个错误了,看起来是hadoop服务没启动,我们先运行/usr/local/hadoop/sbin/start-all.sh:
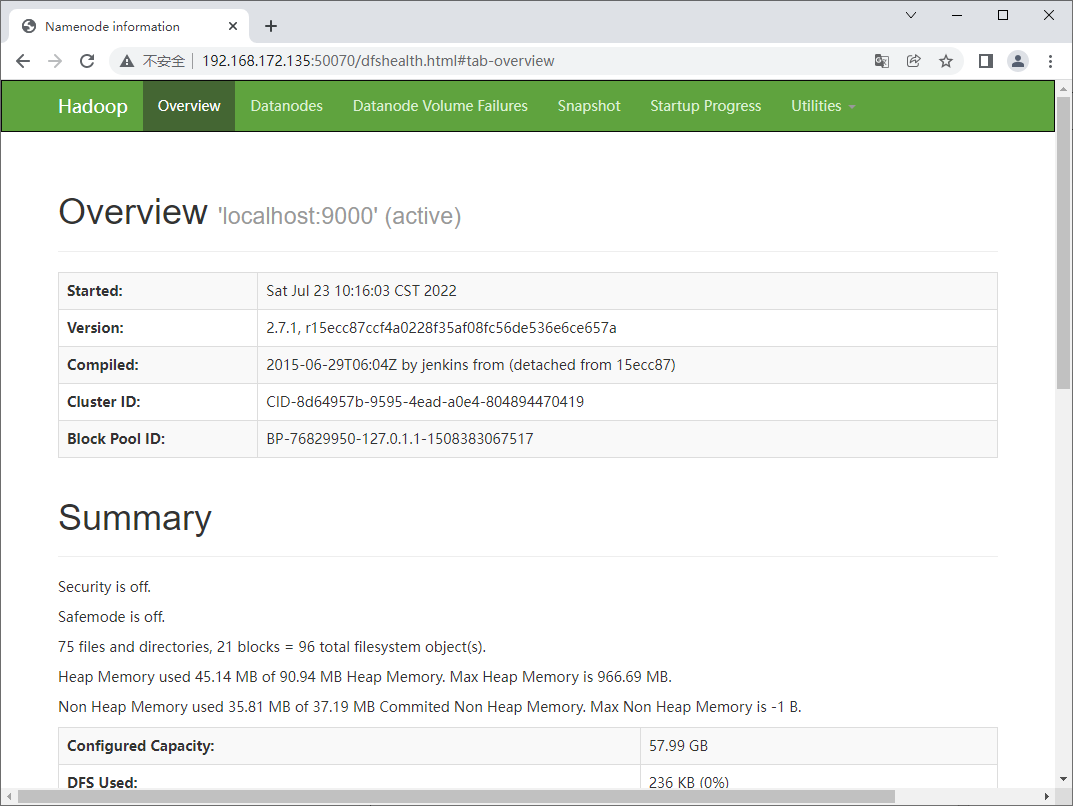
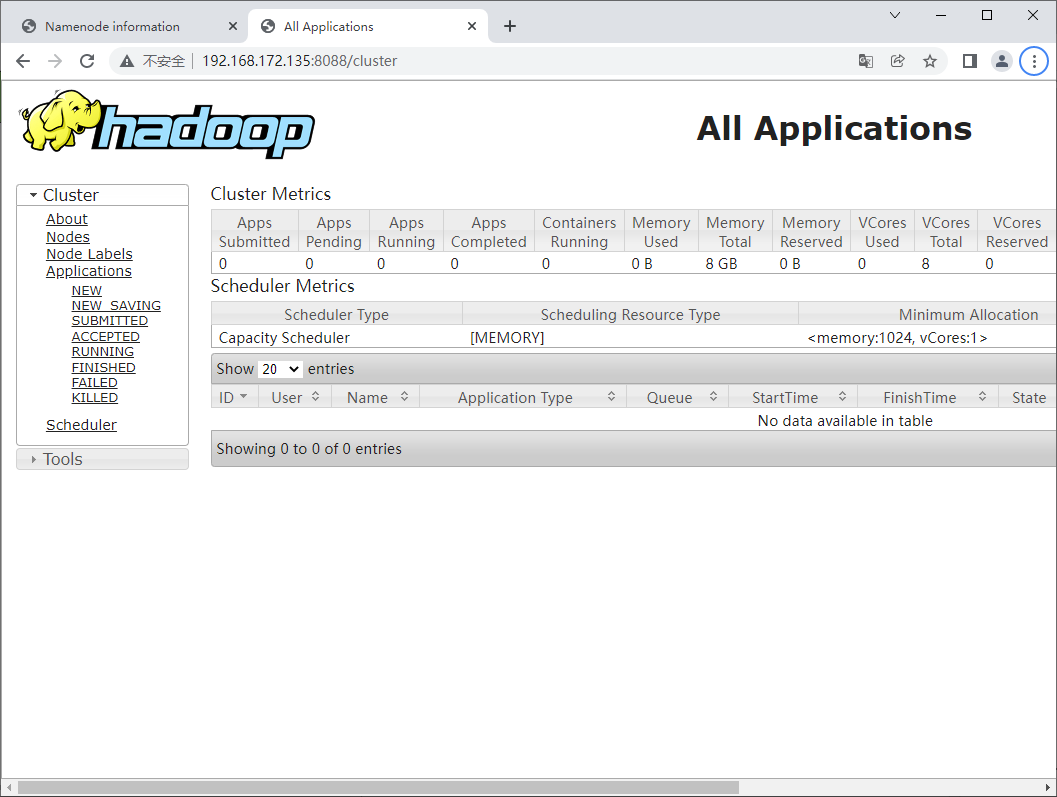
这时可以在浏览器访问50070和8088端口了:
再运行hive命令,可以成功进入hive的SQL命令行了:
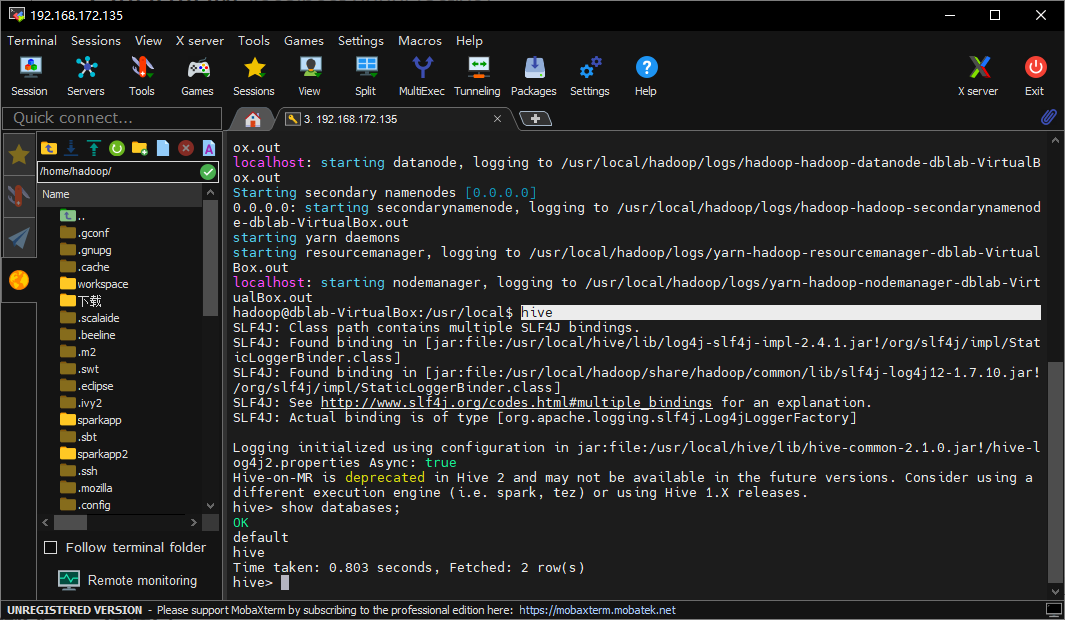
hive测试OK了,我们启动metastore和hiveserver2服务:
1 | hive --service metastore & |
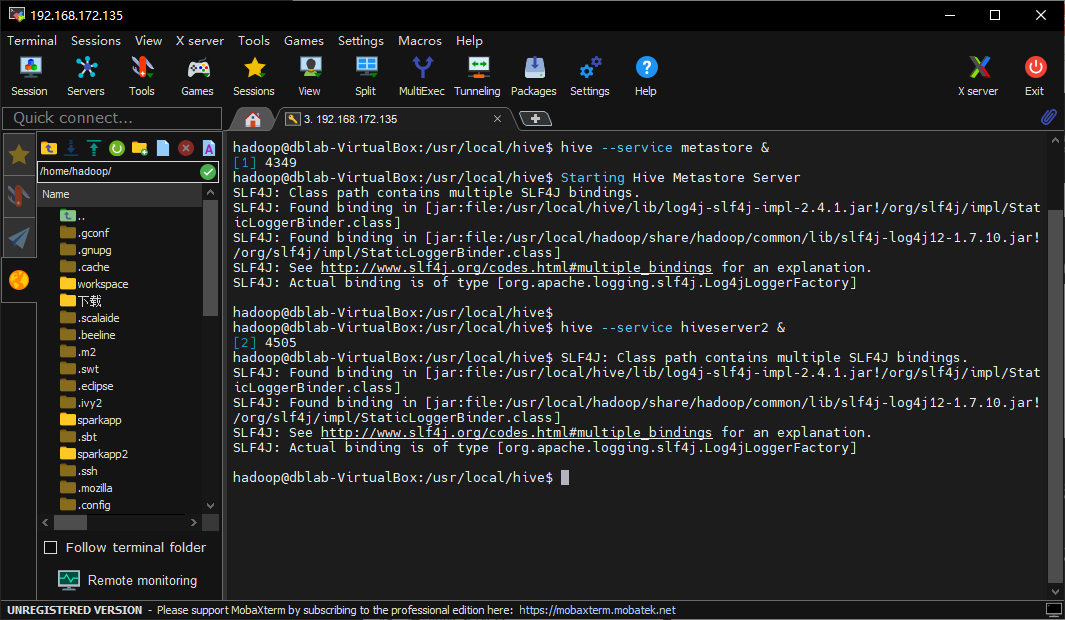
当然,这两命令最好在本机运行,不然可能一不小心把终端关闭了进程就会结束。
使用beeline检测一下:
1 | beeline -u jdbc:hive2://localhost:10000/default |
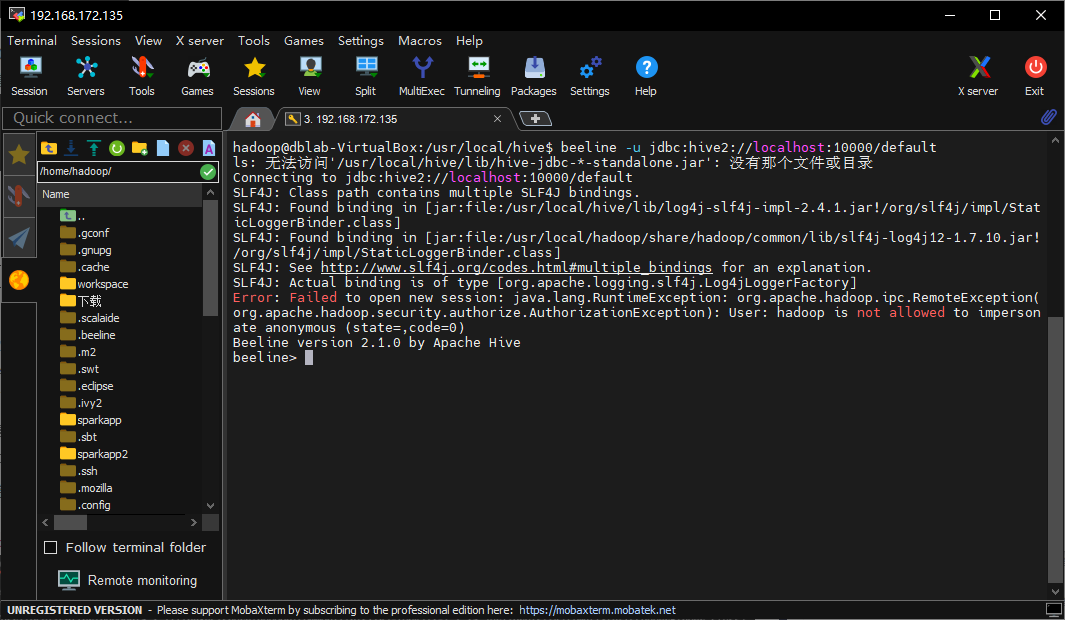
报错说不允许访问,上网搜索了一下,要修改hadoop/etc/hadoop/core-site.xml,增加以下内容:
1 | <property> |
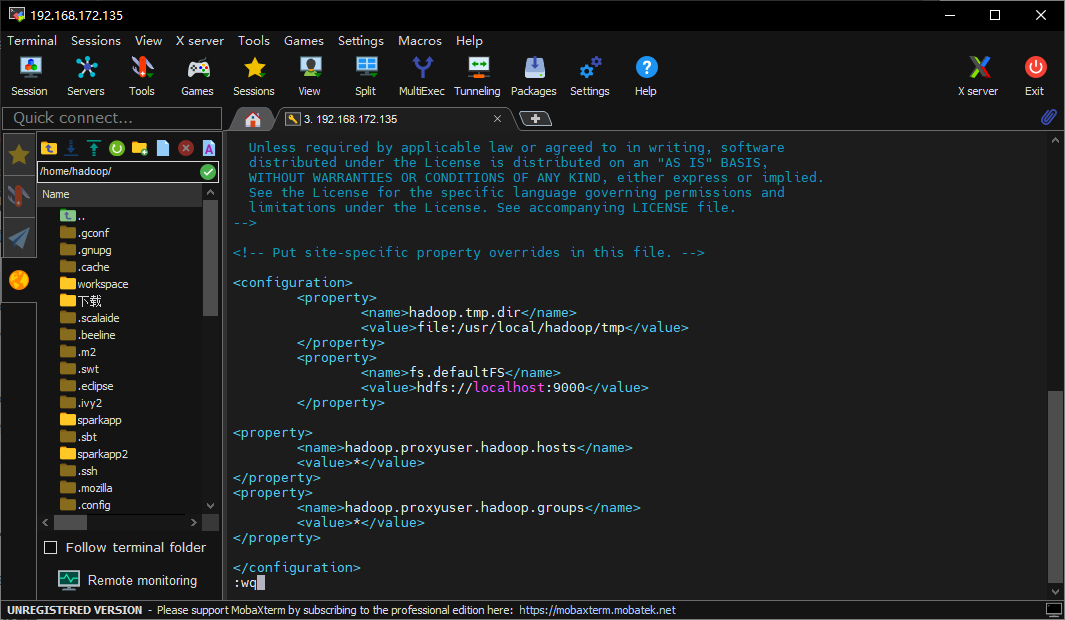
另外,根据网上的文章,为防止权限问题,我们再编辑一下hadoop/etc/hadoop/hdfs-site.xml,添加以下内容:
1 | <property> |
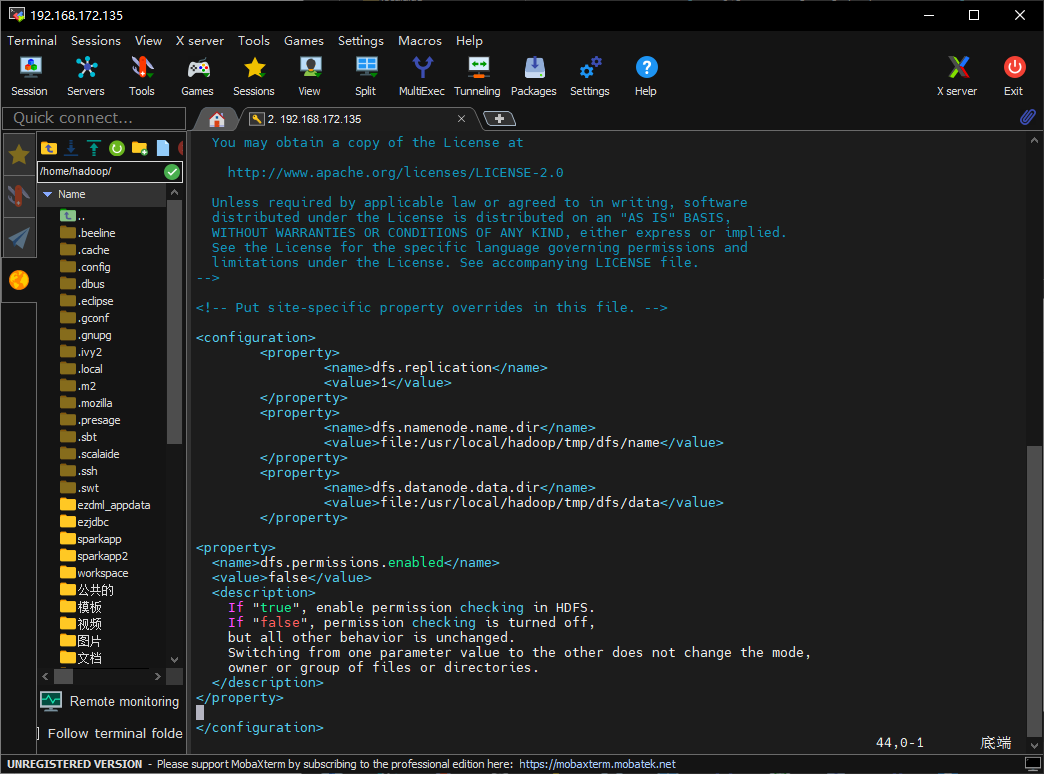
保存,然后重启hadoop服务:
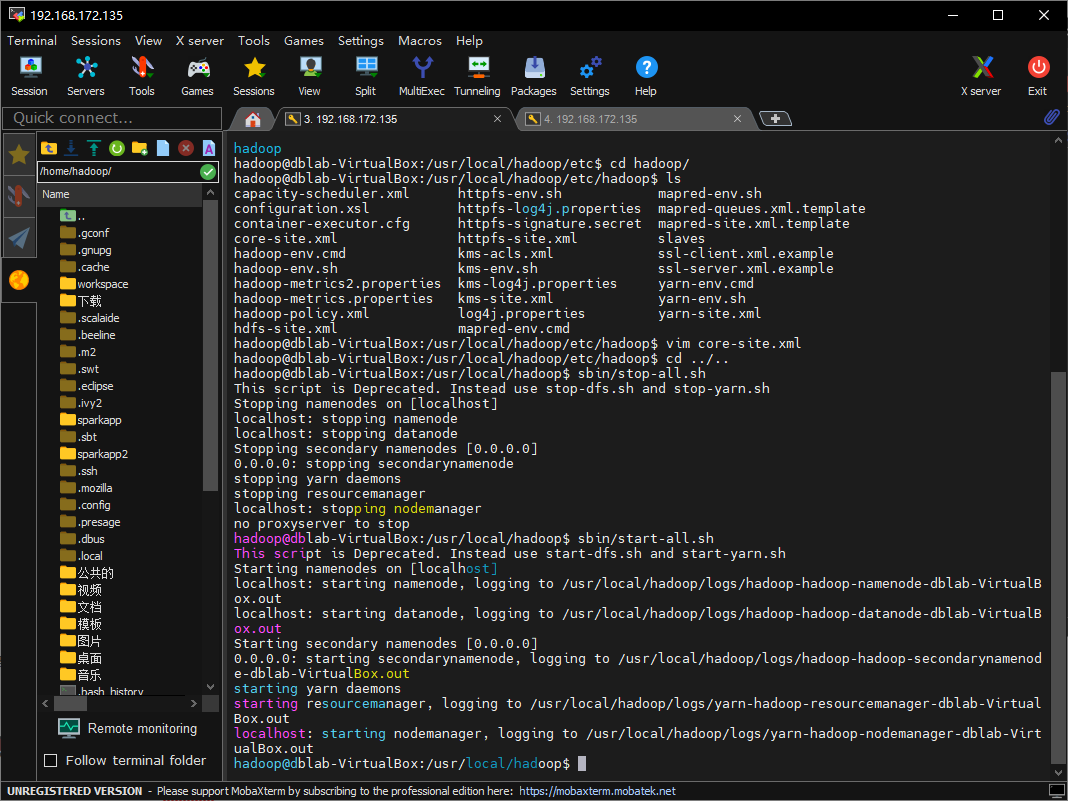
再次运行beeline检测,这回成功连接可以执行SQL命令了:
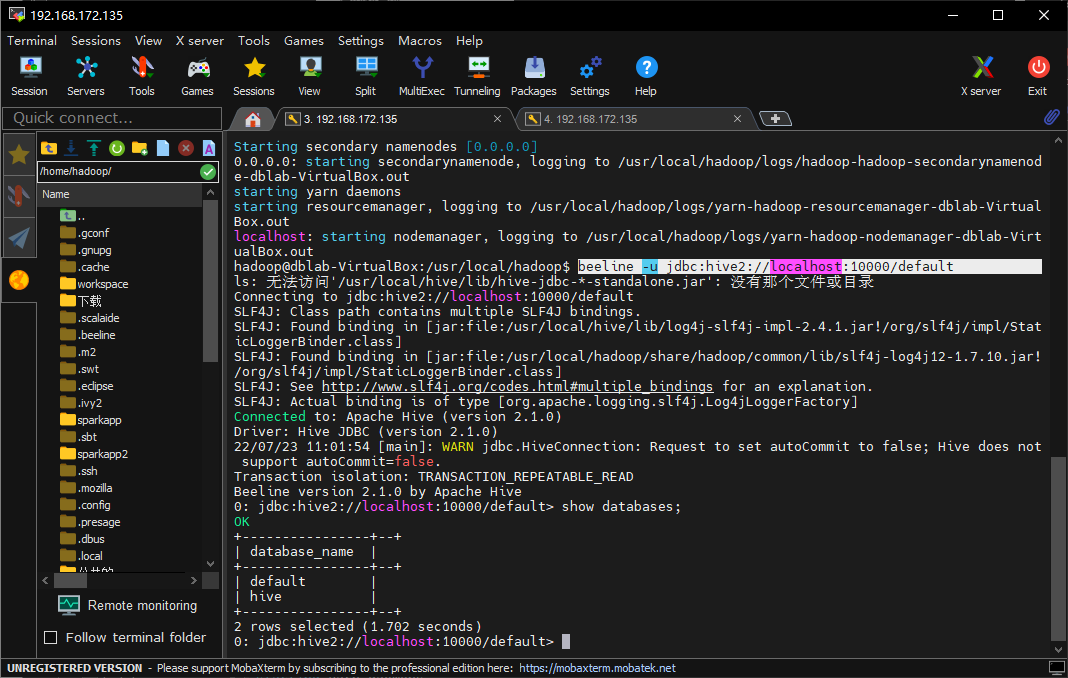
至此,hive的准备工作宣告完成。
测试JDBC连接hive
hive就绪后,我就尝试用EZDML连接。
我用的是EZDML for win64,首先找到EZDML的jdbc子目录下的conf.bat,将内容修改成这样:
1 | @echo off |
然后双击运行ezjdbc.bat,结果如下:
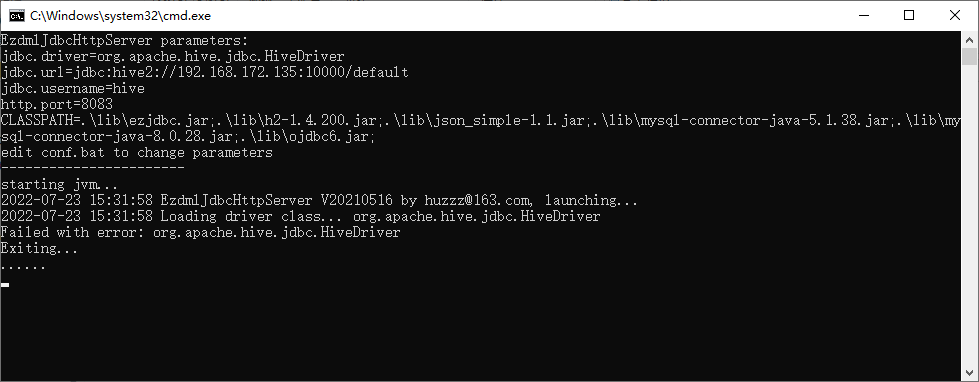
嗯,加载driver失败。显然了,我是在windows下访问,是需要hive的JDBC驱动才能跑的。
这个驱动我瞎折腾了很久,过程不细说了,直接说结论:将hive虚拟机hadoop/share/hadoop/common/下子目录的hadoop-common-2.7.1.jar和hive/jdbc目录下的hive-jdbc-2.1.0-standalone.jar拷出来放到EZDML/jdbc/lib目录下就行了(MobaXterm可以直接把远程的文件拖出来,putty的话估计要用WinSCP下载):
最终运行连接成功:
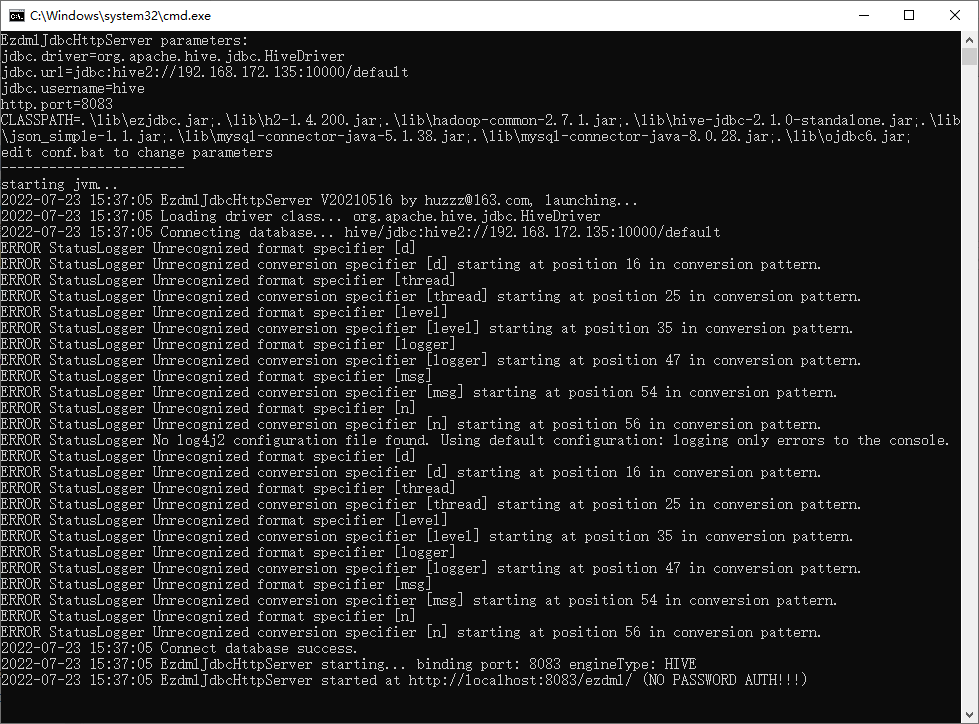
JDBC服务启动成功了。
不过可能还需要其它JAR也是有的,我后来在调试过程中,有一回不小心调了下不知是什么参数,突然连接hive时提示NoClassDefFoundError: com/google/protobuf/ProtocolMessageEnum,只好又去虚拟机上拉了个protobuf-java-2.5.0.jar过来。
如果你用其它工具的JDBC能连上HIVE,也可以将ezjdbc.jar及相关文件拷过去运行(参考ezjdbc.bat)。
如果你是java程序员,你可以直接拉代码,修改pom.xml引用hive驱动,让maven帮你下载JAR包编译运行,这样你就不用操心驱动下载问题。
如果您在windows下跑EZDML,实在找不到可用的驱动,其实还有另一个办法,就是在hive服务器上直接运行,因为EZDML的JDBC服务本质上就是一个JAVA写的jar包,它是可以在linux下运行的(直接用EZDML for linux64也是可以的),而hive的服务器上既有java环境又有所有的jar包,直接用它自带的jar驱动肯定是没问题的。具体我这里就不展开了。
EZDML连接JDBC服务
(注:本节和下两节是使用EZDML之前的旧版3.41自带的ezjdbc.jar出错,新版本EZDML已经解决这个问题并可以直接连接了;保留此三节只是为了说明碰到问题时如何修改EZJDBC服务源码,大家不需要修改相关源码的可以跳过)
这时理论上应该可以用EZDML连接了,我们来试下:
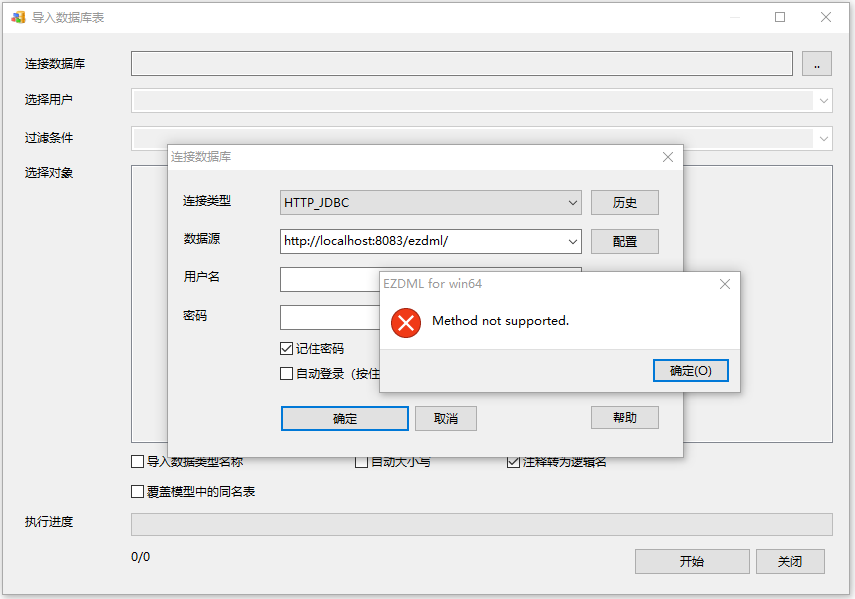
果然连接出错了,Method not supported,大概意思是某个方法不支持。网友诚不我欺也,看下错误堆栈:
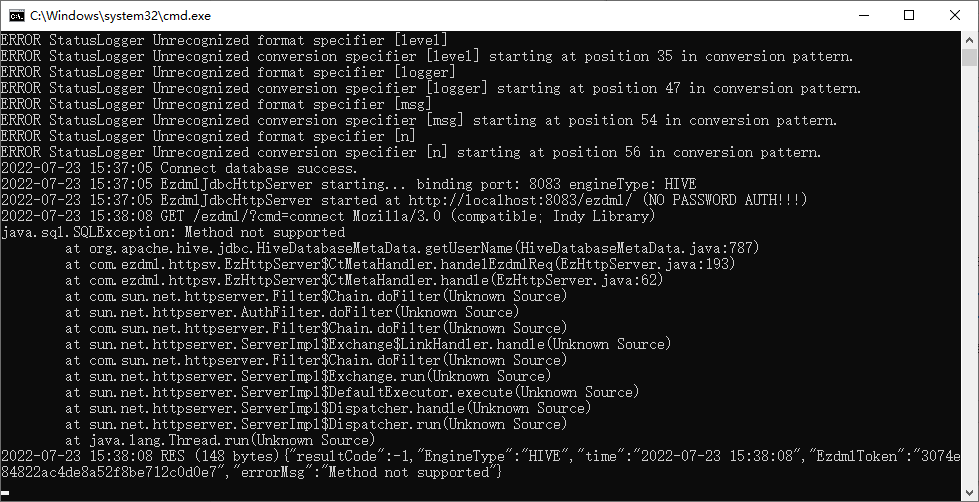
看起来是获取用户名出错了,免不了要改代码了。
拉取JDBC代码并搭建编译环境
(注:本节和上下节是使用EZDML之前的旧版3.41自带的ezjdbc.jar出错,新版本EZDML已经解决这个问题并可以直接连接了;保留此三节只是为了说明碰到问题时如何修改EZJDBC服务源码,大家不需要修改相关源码的可以跳过)
为方便有需要的朋友,我这里也演示下如何拉取EZDML的JDBC服务代码并搭建编译环境,熟练的可以跳过此节。
首先是从gitee获取最新的代码,最新的代码在这里可以获取到:
1 | https://gitee.com/huzgd/ezdml/tree/master/jdbc/EzdmlJdbcServer |
它隶属于ezdml仓库,用git克隆整个仓库:
1 | https://gitee.com/huzgd/ezdml.git |
然后在jdbc/EzdmlJdbcServer子目录下就能找到JDBC服务源码了:
我们用idea导入,这个工程导入后理论上是可以直接编译运行的:
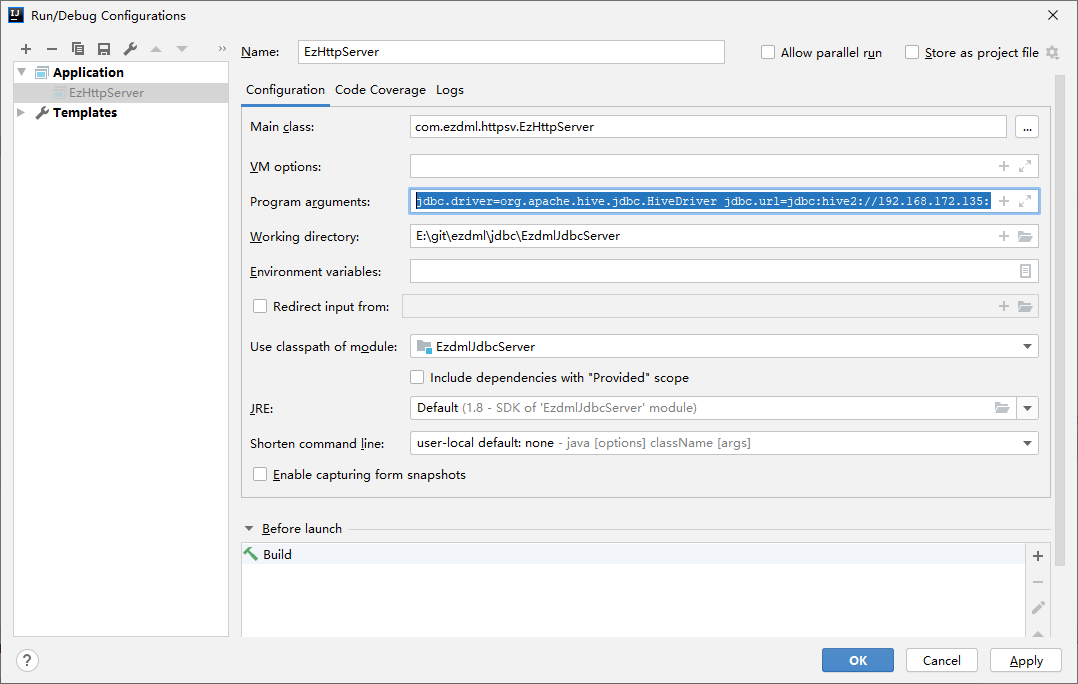
不过,它需要设置运行参数,我们设置它的启动参数如下:
1 | jdbc.driver=org.apache.hive.jdbc.HiveDriver jdbc.url=jdbc:hive2://192.168.172.135:10000/default jdbc.username=hive jdbc.password=hive jdbc.engineType=HIVE http.password= http.port=8083 |
再次运行:
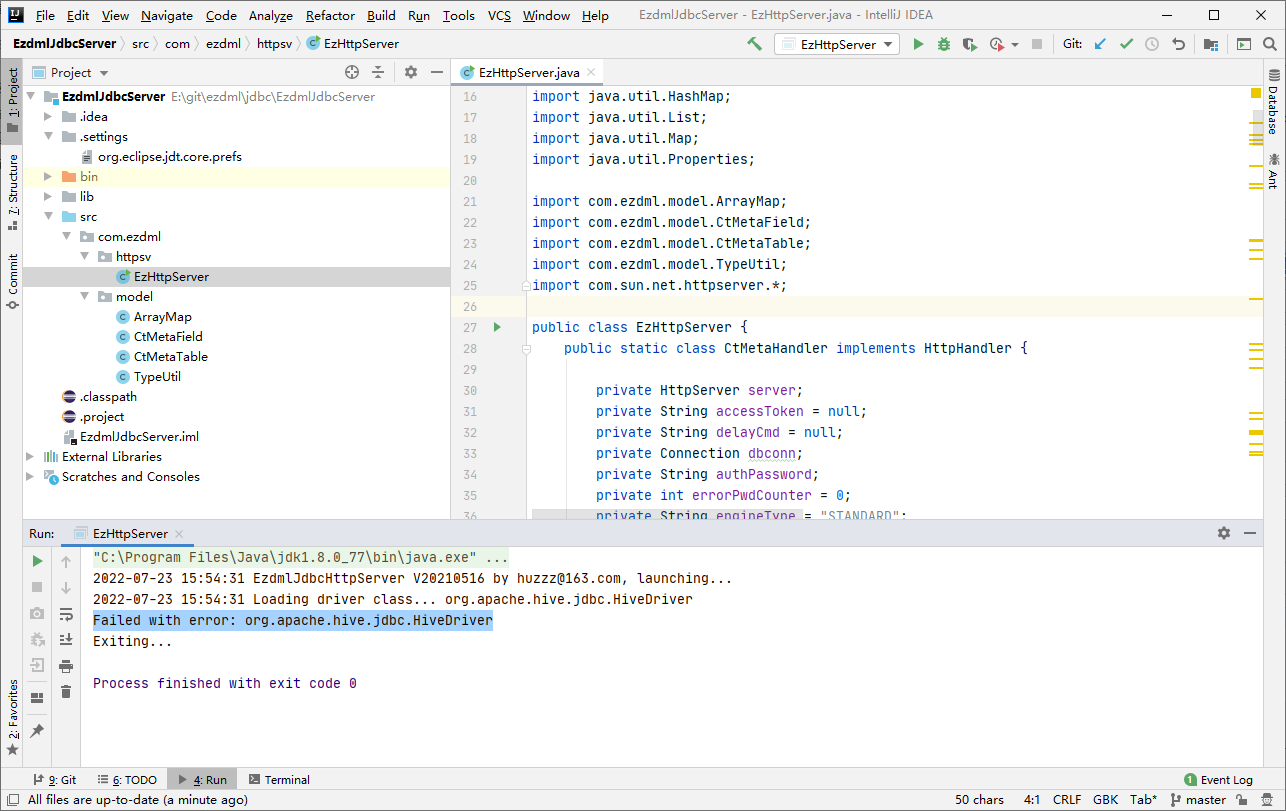
嗯,缺JDBC驱动,我们把那两个jar拷到lib目录并加到工程里:
再次运行:
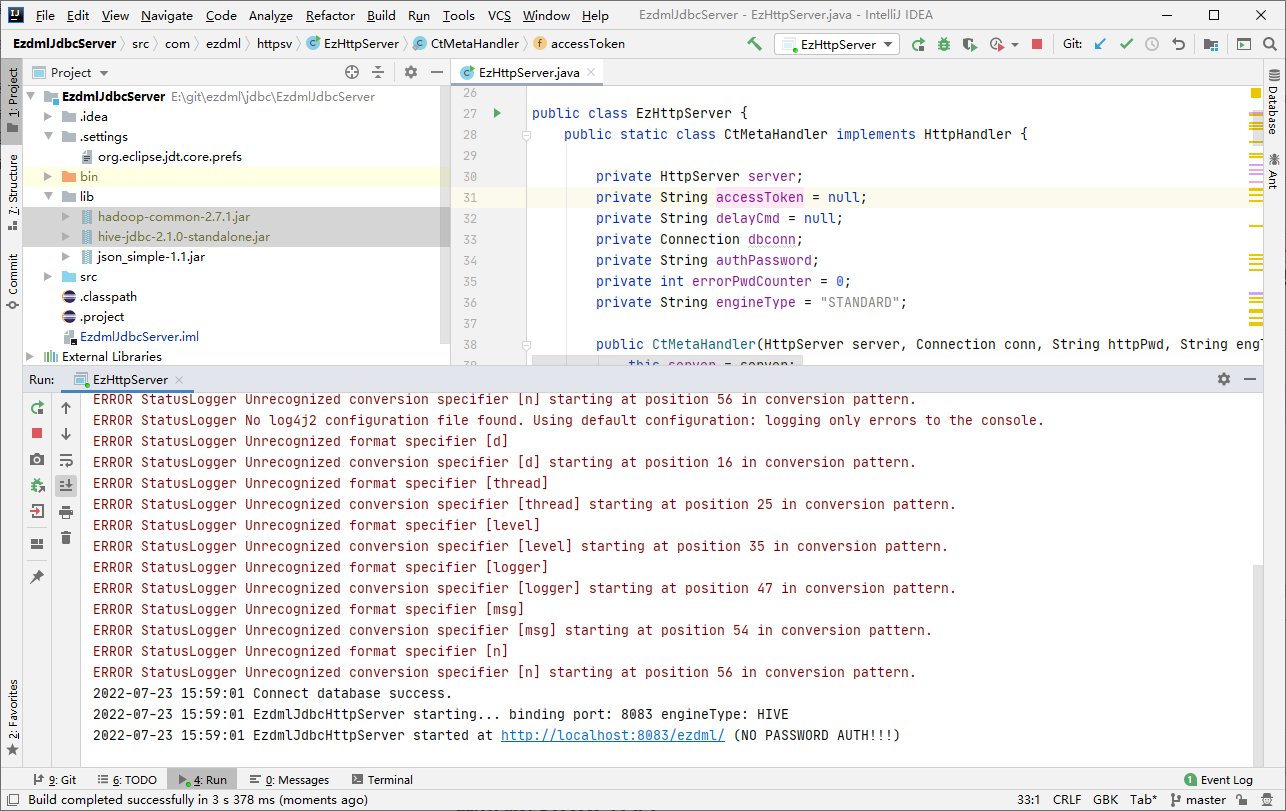
运行OK了,连上hive了,接下来我们看看如何调试修改。
调试修改JDBC代码
(注:本节和上两节是使用EZDML之前的旧版3.41自带的ezjdbc.jar出错,新版本EZDML已经解决这个问题并可以直接连接了;保留此三节只是为了说明碰到问题时如何修改EZJDBC服务源码,大家不需要修改相关源码的可以跳过)
编译运行起来后,我们再次用EZDML连接,果然又报“Method not supported”的错误了,错误堆栈代码定位在meta.getUserName这一行:
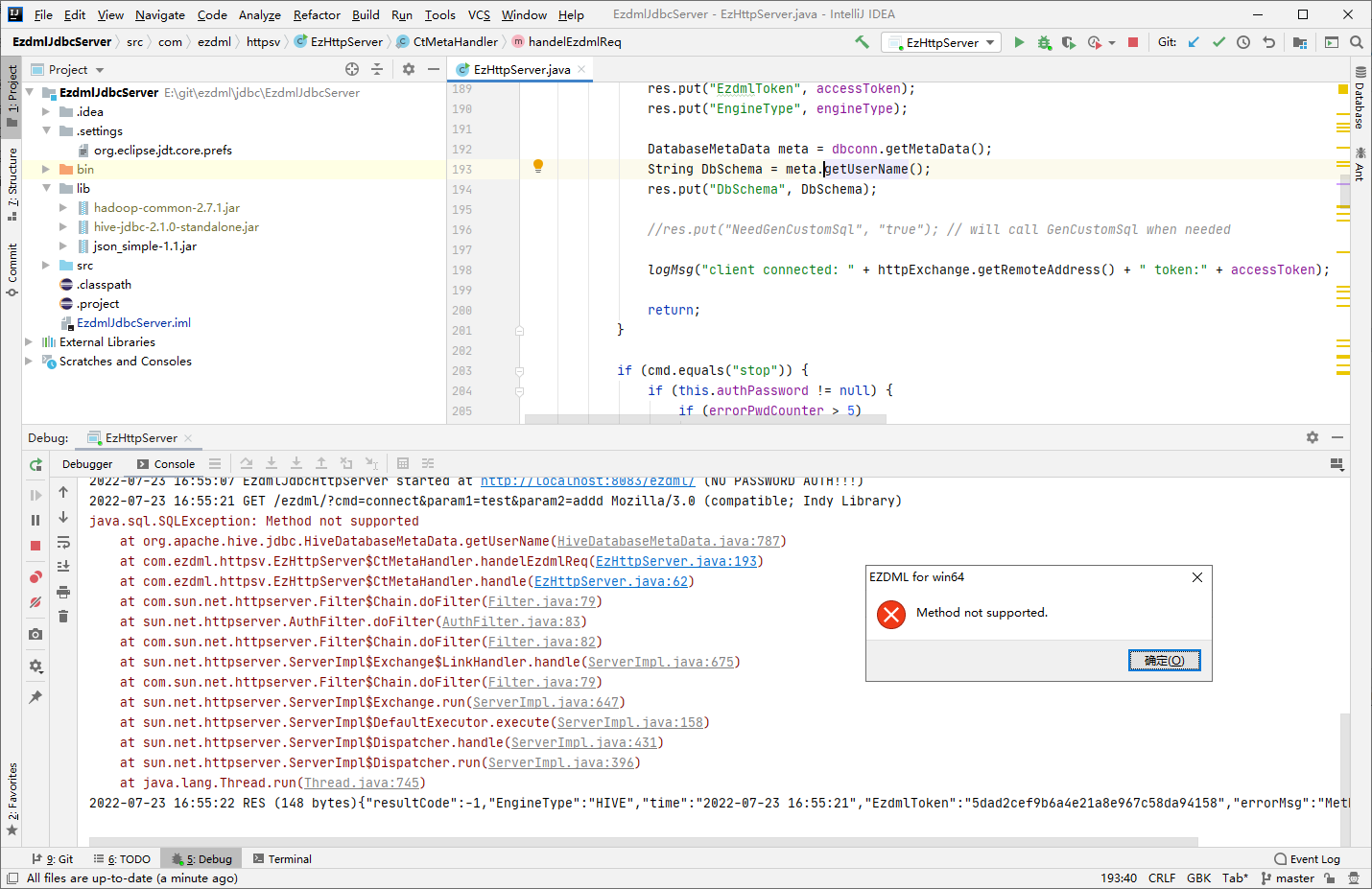
嗯,这个getUserName是为了告诉EZDML当前连接的用户模式名DbSchema,估计hive不支持这个,不过这个DbSchema不回传也没什么问题,我们直接把错误try掉,再试:
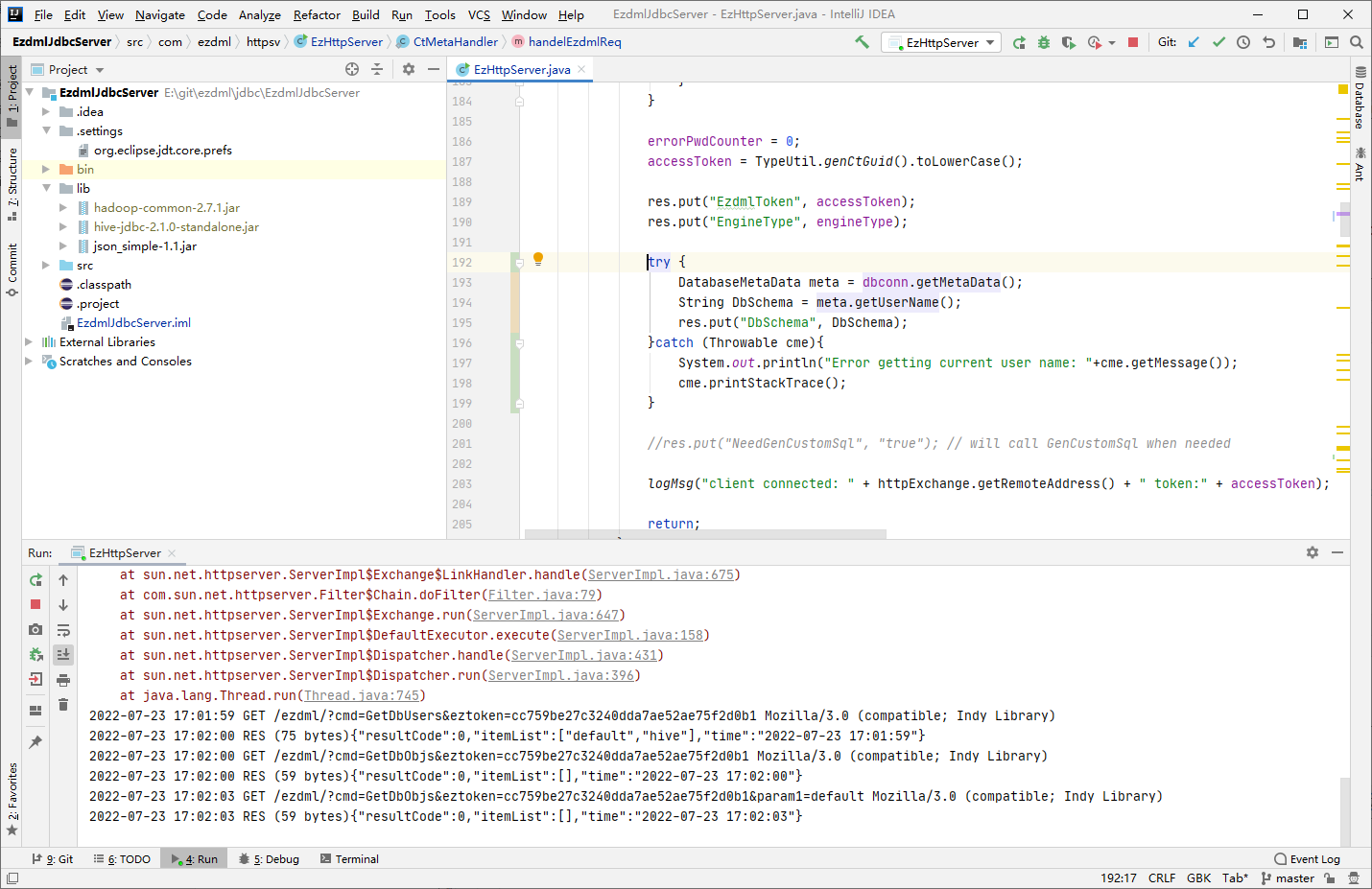
连接成功了,不过目前数据库是空的:
另外,我还修改了其它几处Java代码,包括导入map、array类型的,并增加了pom.xml,方便大家用maven下载驱动JAR包。
最新的JDBC服务代码已经提交到gitee,大家可以直接拉下来跑。
1 | https://gitee.com/huzgd/ezdml/tree/master/jdbc/EzdmlJdbcServer |
导入hive数据表
我们通过hive创建一个带中文注释的测试表:
1 | CREATE TABLE IF NOT EXISTS employee ( |
然后再用EZDML导入:
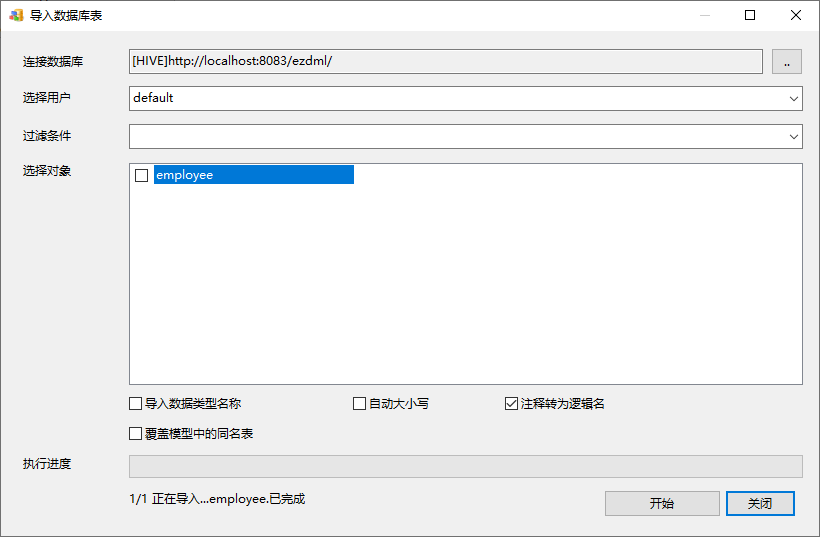
确实导入成功了,不过,中文是乱码:
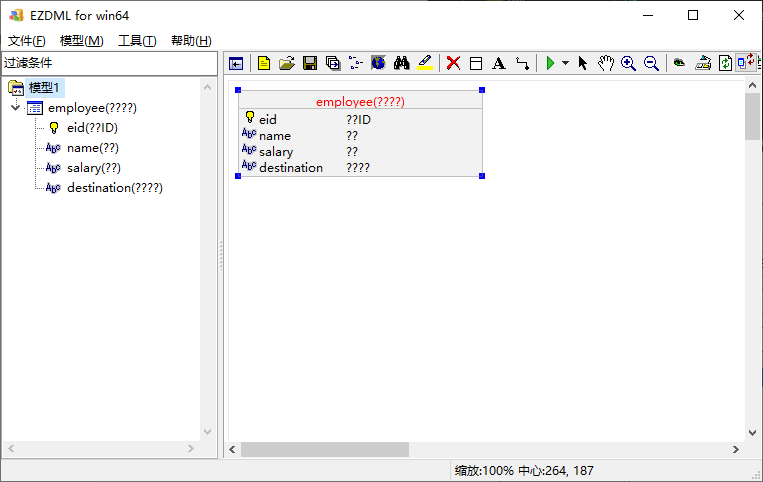
再检查一下,发现它自己的命令行出来也是乱码:
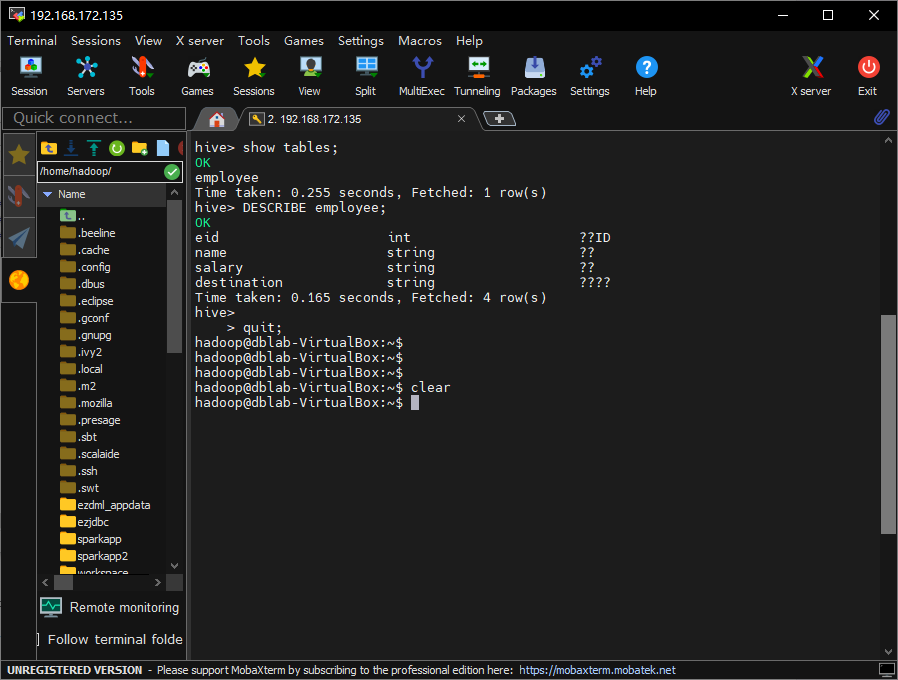
这就不是我的错了。上网搜索了一下,大概是因为mysql中存储的元数据不支持UTF8,需要在mysql中执行以下命令设置:
1 | alter table TBLS modify column TBL_NAME varchar(1000) character set utf8; |
注意是MYSQL中执行:
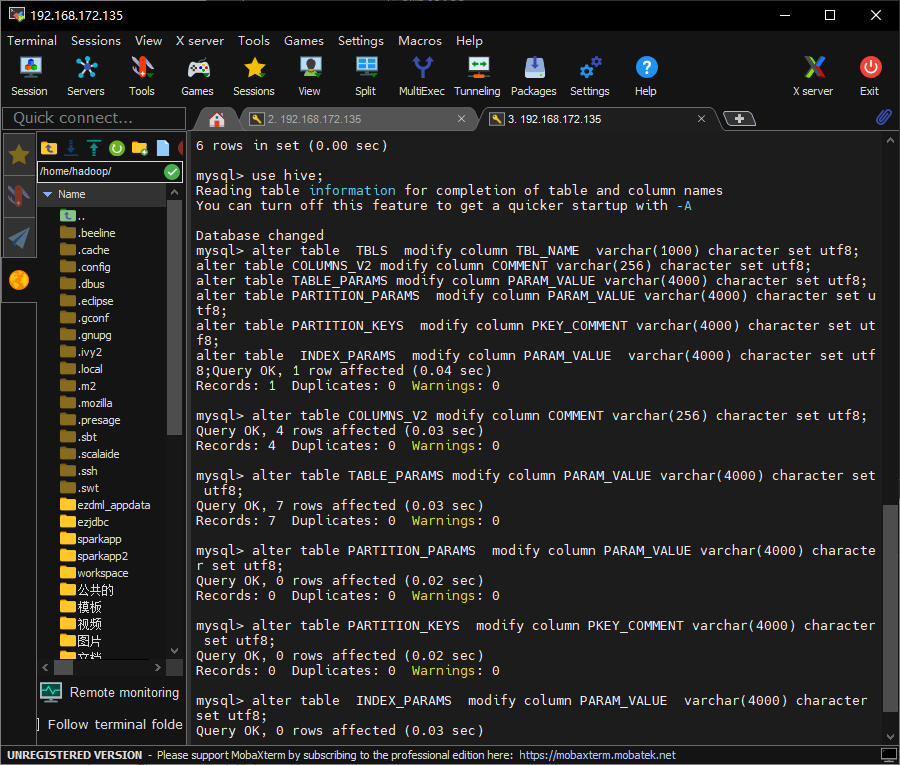
执行完成,重新创建表,并检查,没有乱码了:
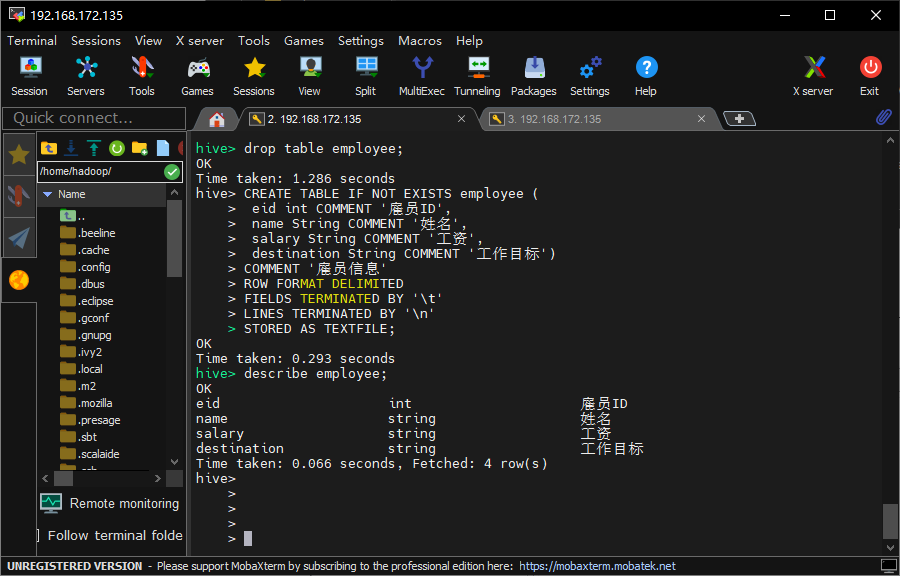
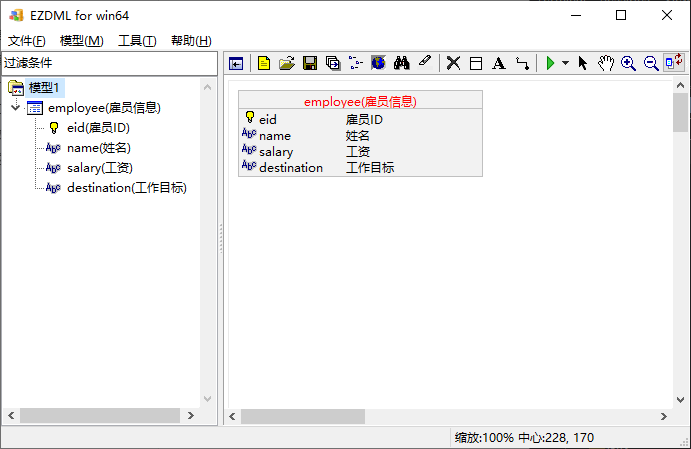
回到EZDML,再次导入,这回中文正常导入成功了:
EZDML新版支持HIVE
(注:本节中的问题是因为使用EZDML之前的旧版3.41导致,新版本EZDML已经解决了)
文章写到这里,到生成SQL时,突然发现接下来有点玩不下去了,因为hive的SQL语法跟关系数据库的有较大差异,EZDML生成的SQL没有一种是跟hive兼容的。而且hive还不支持类似 / * xxx * / 这种跨行的注释。
如何才能支持hive的SQL语法,我面临两个选择:
- 继承修改java代码,由JAVA代码实现对HIVE的支持(EZDML支持把生成SQL的工作交给JDBC服务,感兴趣的同学可在源码中搜索GenCustomSql)
- 直接修改EZDML的Pascal代码,增加一个全新的HIVE类型的数据库方言
我琢磨了半天,决定还是改EZDML的代码,增加对HIVE的支持。java代码虽然预留了自定义SQL功能,但那毕竟只是为了生成数据库SQL时作轻微小改动用的,HIVE这个我感觉要改的地方很多,还是花点时间折腾一下吧。
EZDML的核心代码上传到gitee了,因此也简单讲一下我如何添加HIVE的支持。
首先是修改DML/CtMetaTable.pas,添加HIVE的默认数据类型:
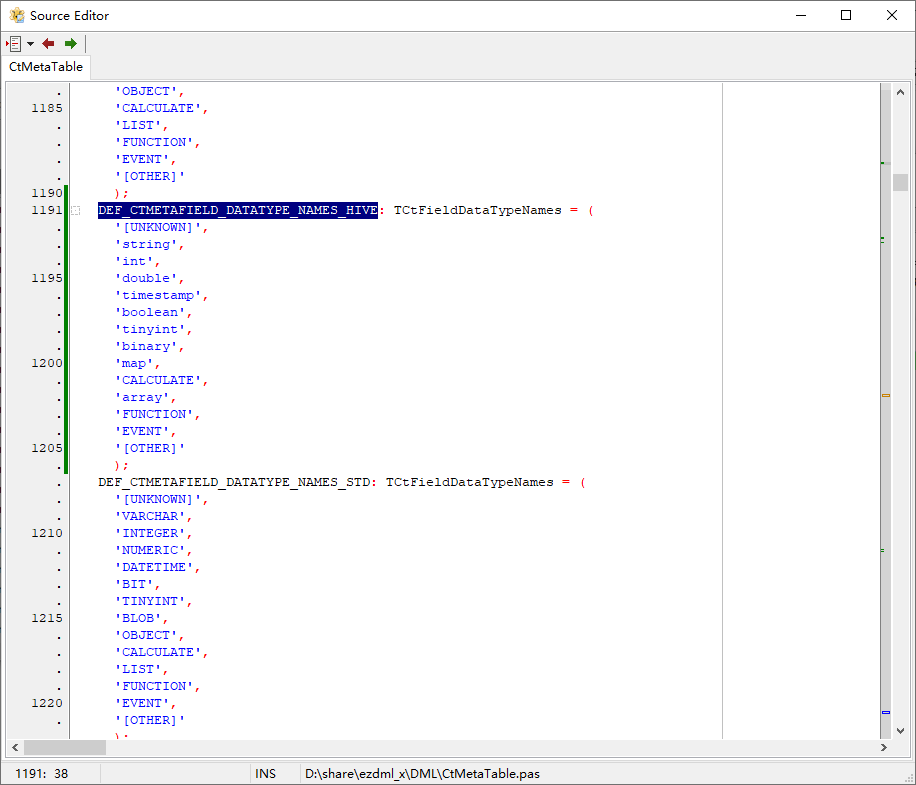
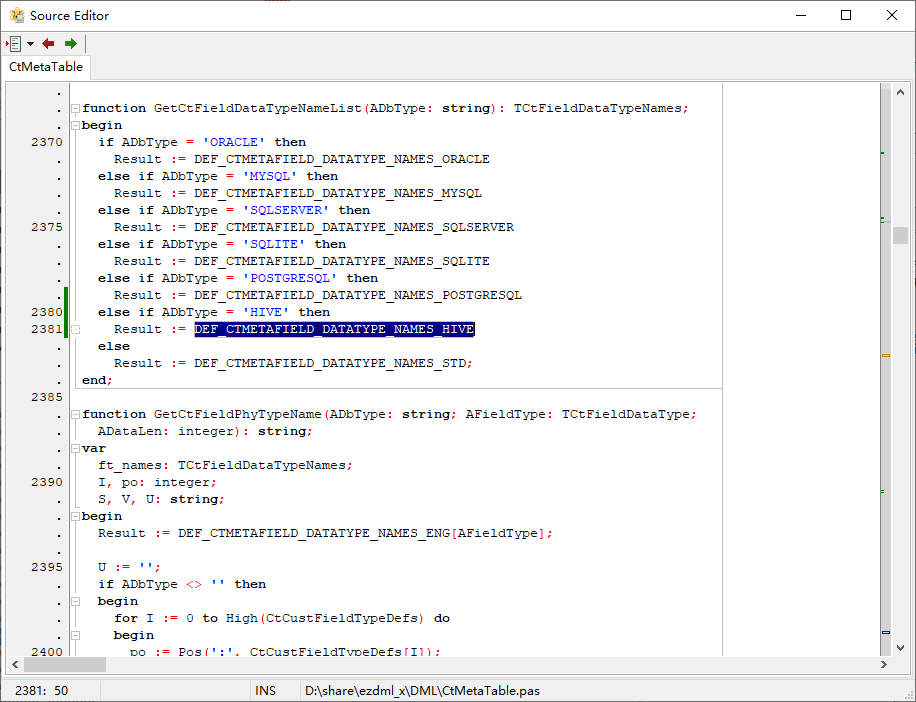
并在相关的地方添加判断引用(查找POSTGRESQL,把POSTGRESQL的所有代码复制一份改一下):
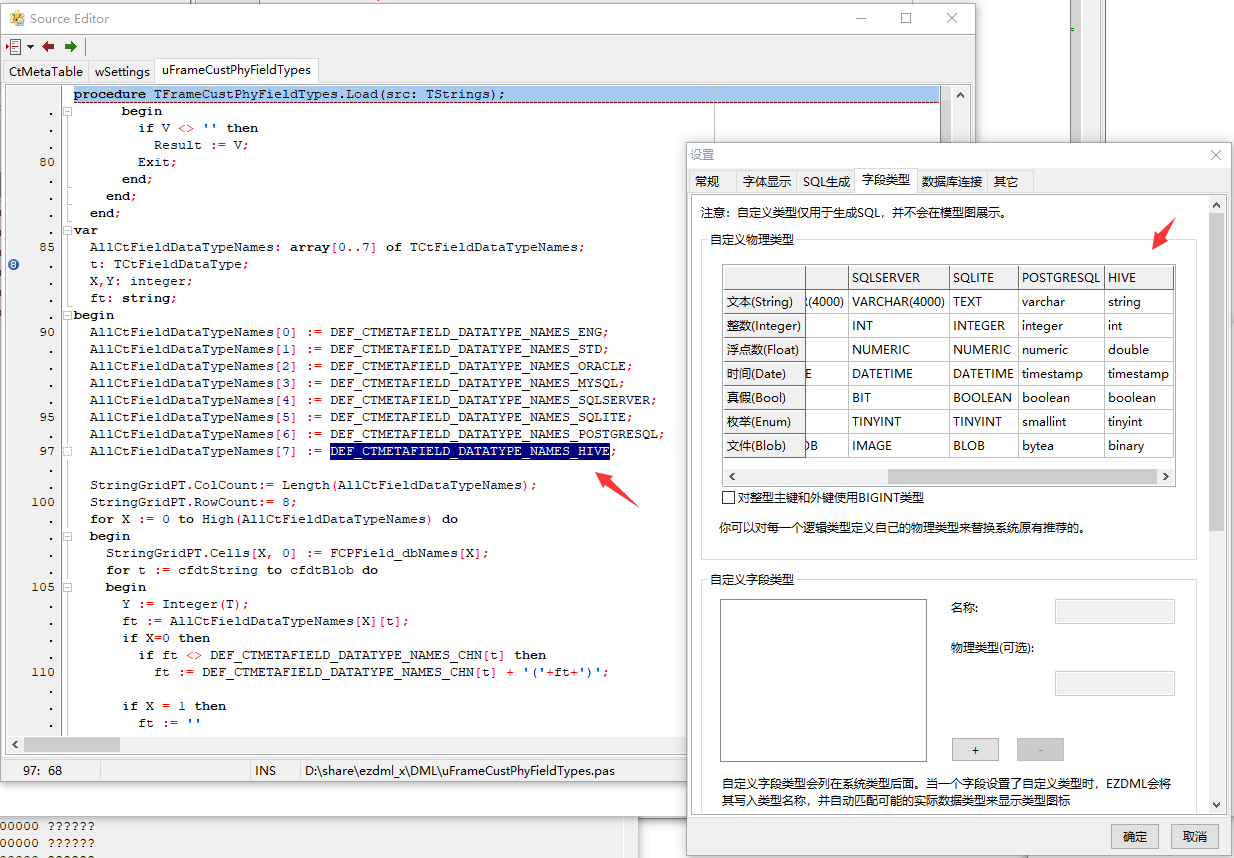
自定义数据类型设置也要相应增加:
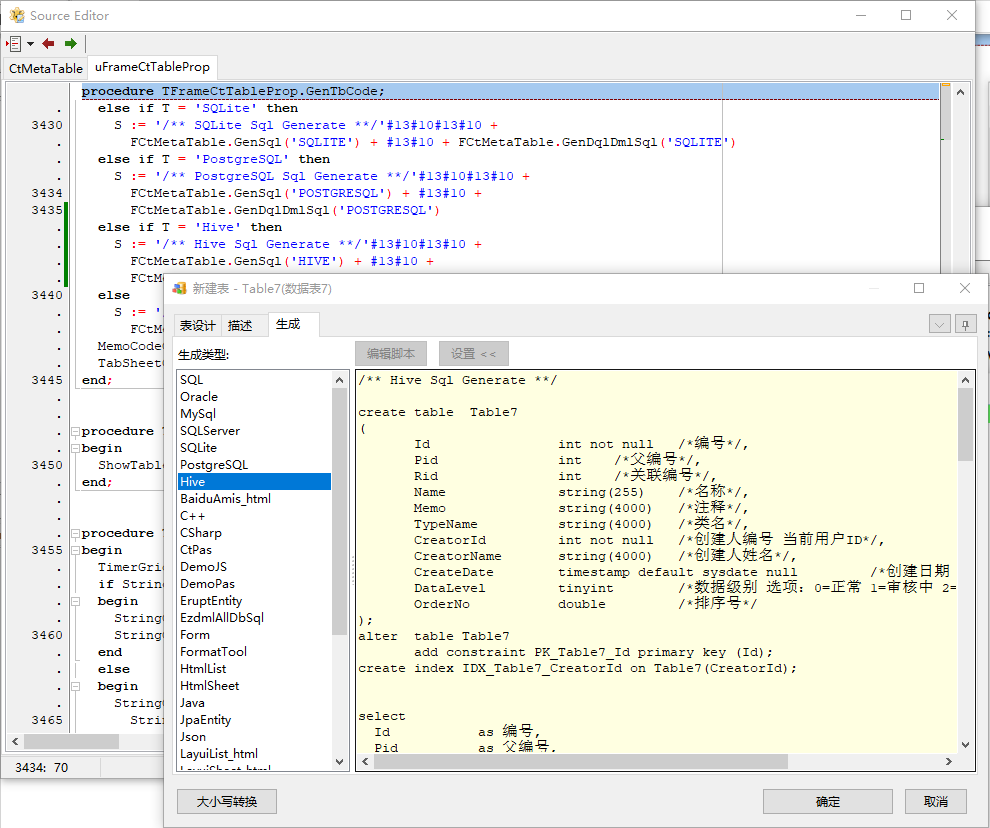
表属性也加上,这时已经能生成SQL了:
不过细节还有点问题,string类型应该是不需要长度的,有长度的要转成varchar,我们修改一下TCtMetaField.GetPhyDataTypeName这个方法:
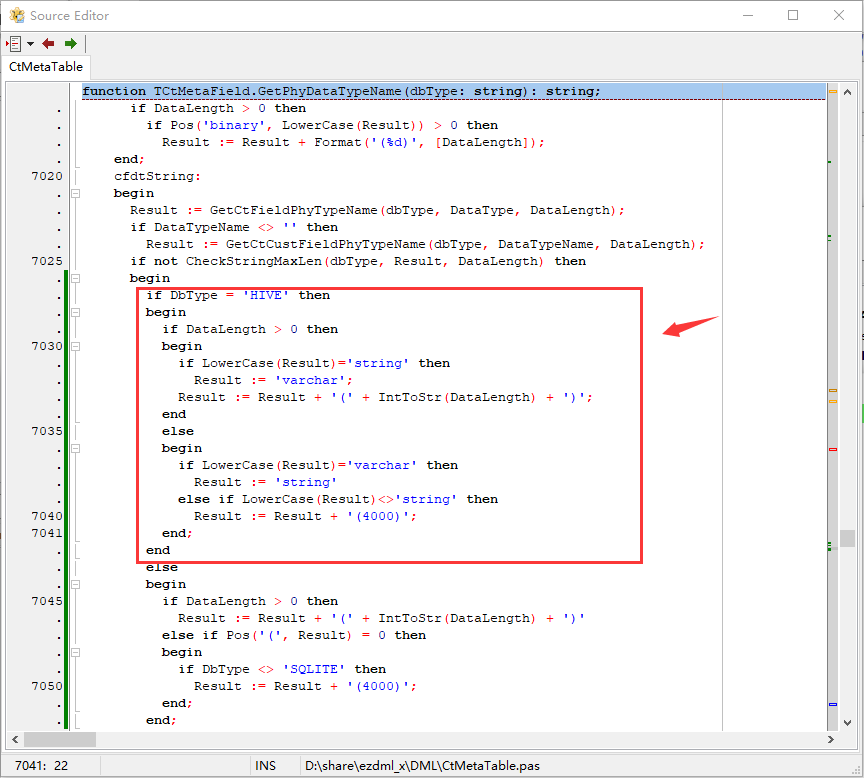
再生成就好了,不指定长度的字符串为string类型,有长度的则为varchar:
不过还是有一些问题,需要继续改进。
EZDML默认生成SQL的代码主要有两个地方,都是在DML/CtMetaTable.pas里:
- TCtMetaTable.GenSqlEx:生成创建表的SQL
- TCtMetaDatabase.GenObjSql:与数据库比较,生成修改表的SQL
我对其中一些内容为HIVE进行专门处理,大家在拉取新代码后查找HIVE就能找到我改过的地方了。
除了这两个地方,还有其它一些细节,这里就不一一展开了。总之最后我们改了一个新版本3.42出来,这个版本勉强支持HIVE了。
生成hive数据库SQL
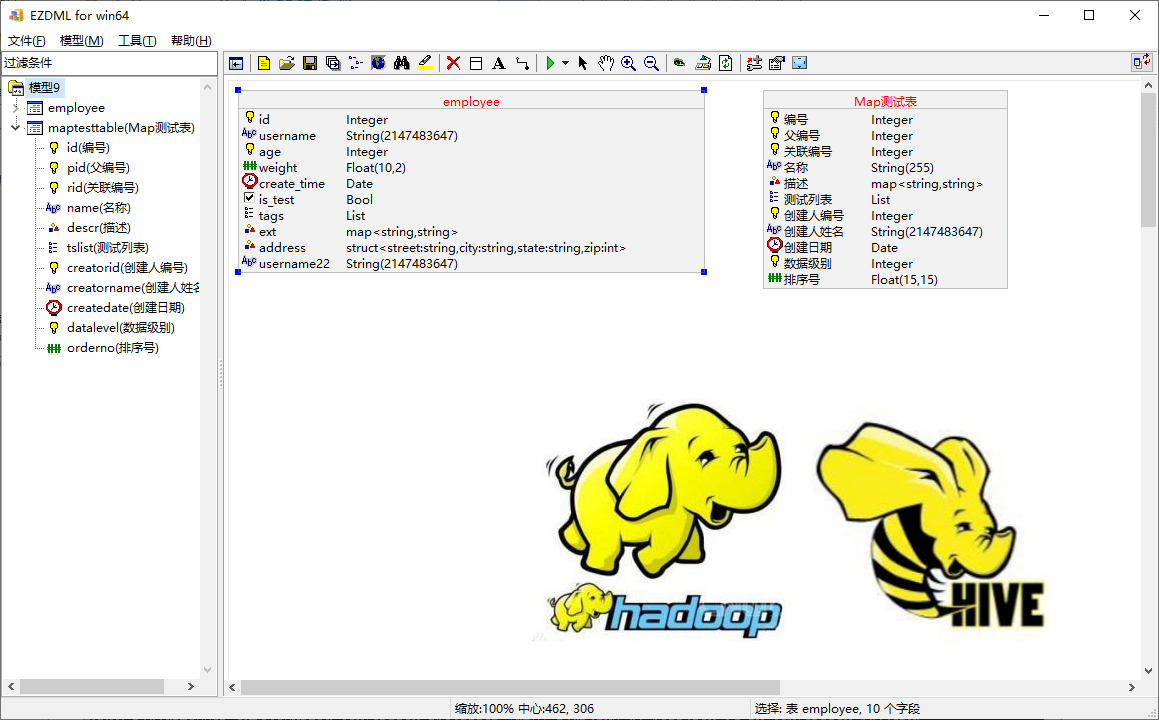
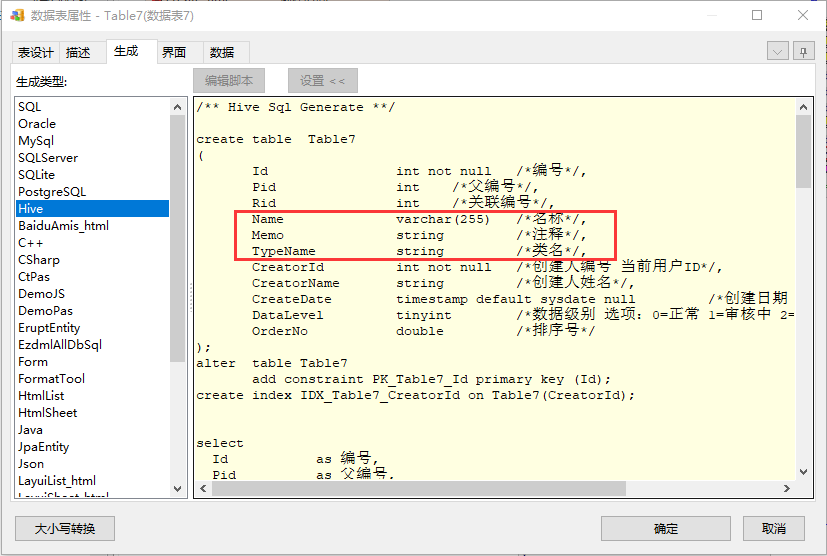
我们再新建一个表,输入以下描述字内容(这里我加了map和array的演示字段):
1 | MapTestTable(Map测试表) |
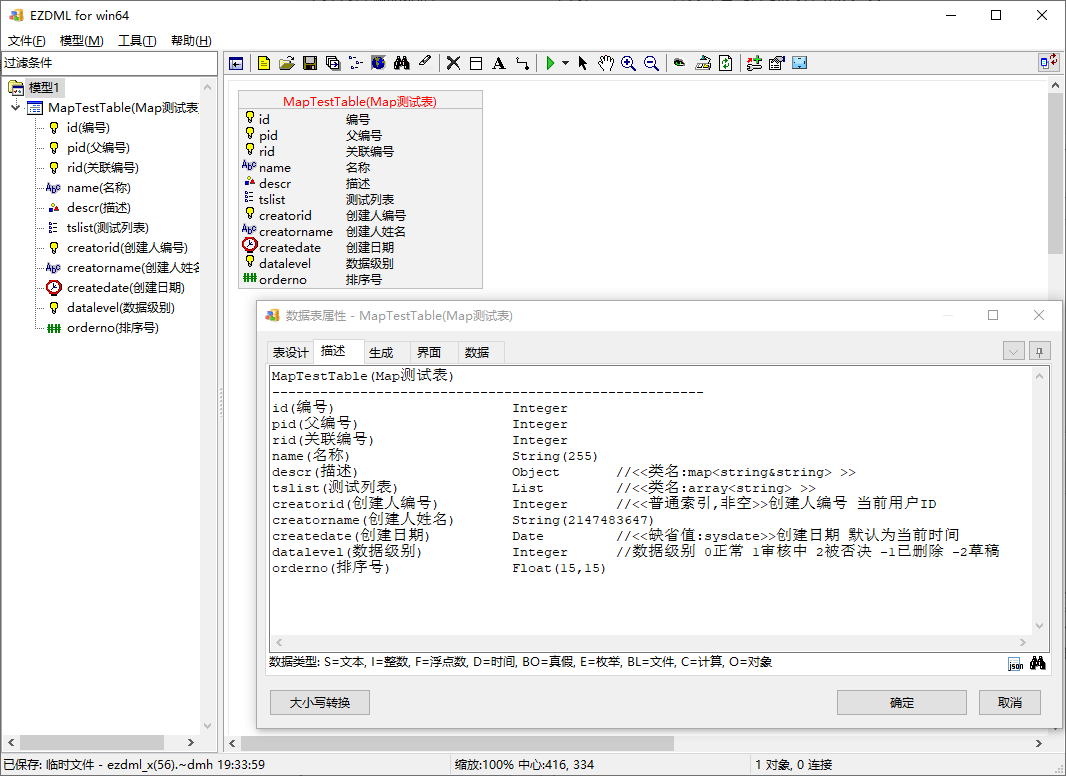
生成数据库SQL:
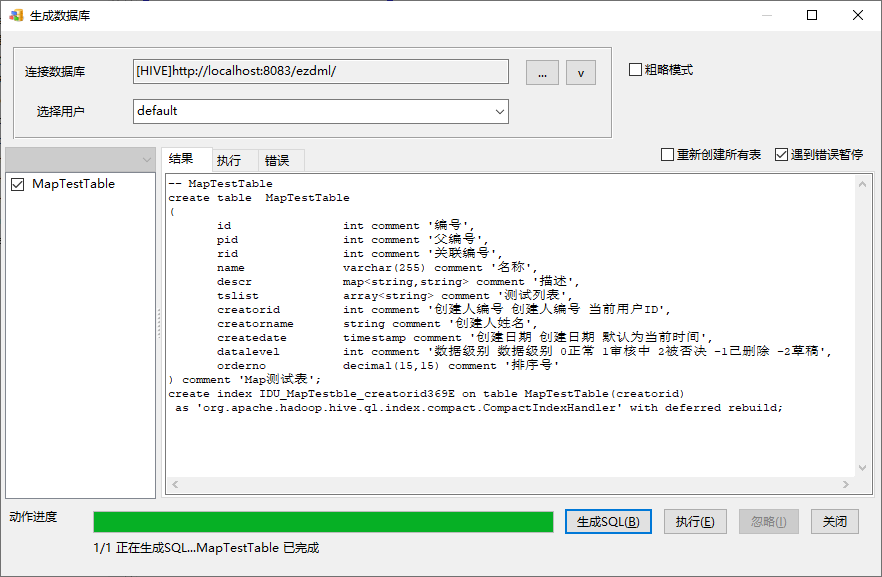
执行:
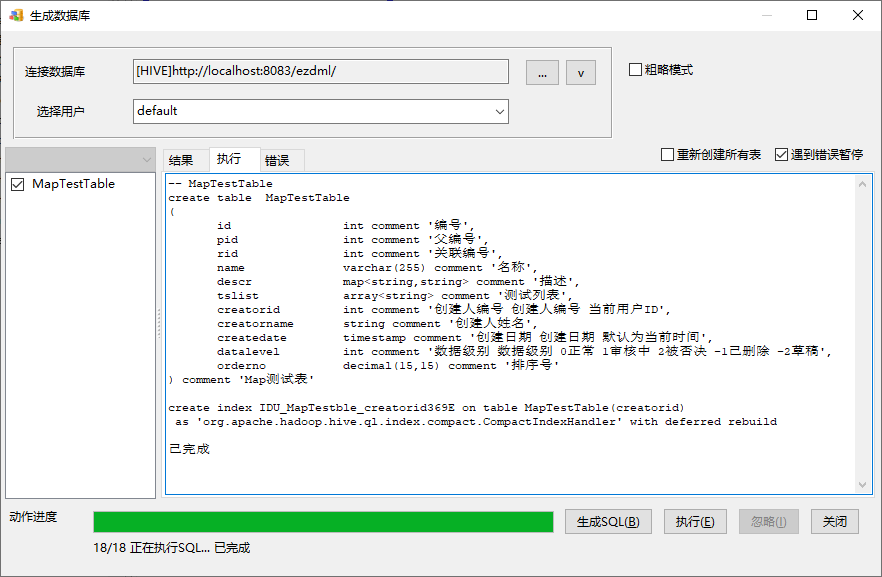
然后我试着把EZDML自带的demo文件的第一个模型图也生成了一下(先要关闭SQL生成设置里保留字的引号),执行也是OK的:
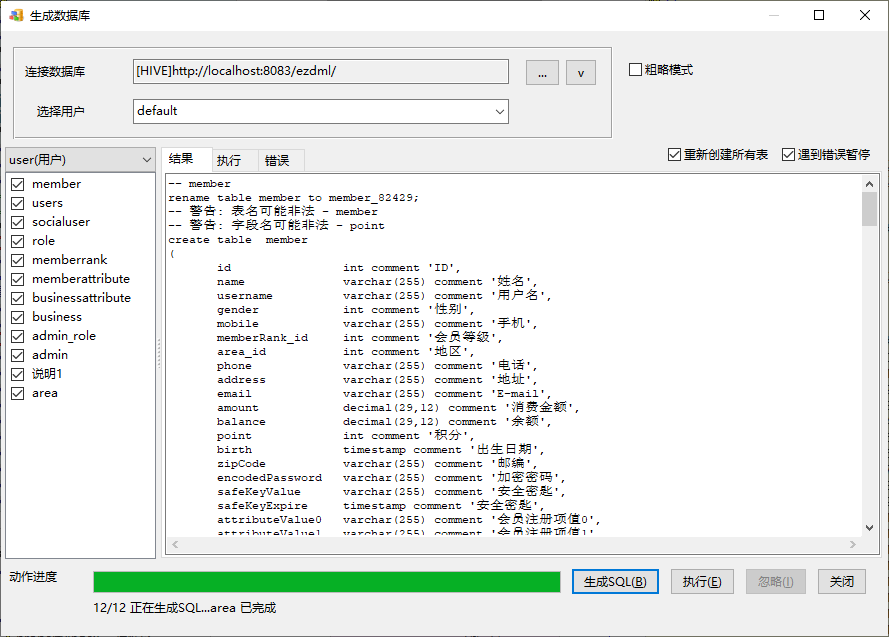
至此HIVE数据库生成完毕。试了下执行select SQL查看数据,也是可以的:
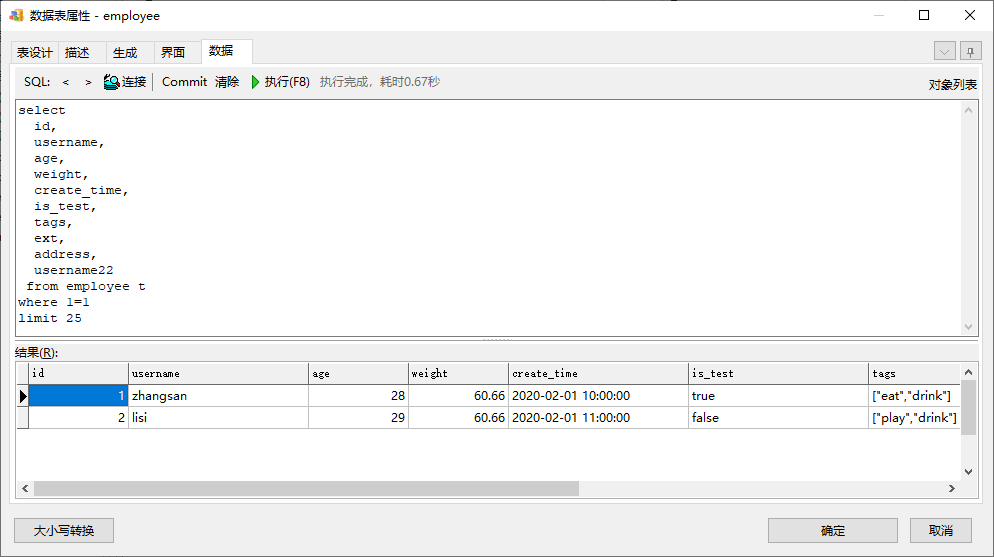
另外也试了一下生成测试数据的SQL,不过执行insert语句的速度太慢了,insert一条记录居然要十几二十秒,没什么意义,还是用Load data指令加载文件靠谱。
小结
EZDML能支持HIVE了,你需要使用3.42以上版本的EZDML,带最新的ezjdbc.jar(EzdmlJdbcServer),你还需要有hive的JDBC驱动相关的一堆jar,虽然还比较麻烦,效果也不完美,但总算是从无到有零的突破了。